
1. 字符集与字符编码
1.1. 字符集
字符集(Charcater Set或Charset): 是一个系统支持的所有抽象字符的集合,也就是一系列字符的集合。字符是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。常见的字符集有:ASCII字符集、GB2312字符集(主要用于处理中文汉字)、GBK字符集(主要用于处理中文汉字)、Unicode字符集等。
1.2. 字符编码
字符编码(Character Encoding): 是一套法则,使用该法则能够对自然语言使用的字符集(如字母表或音节表),与计算机能识别的二进制数字进行配对。即它能在符号集合与数字系统之间建立对应关系,是信息处理的一项基本技术。通常人们用符号集合(一般情况下就是文字)来表达信息,而计算机系统则是以二进制的数字来存储和处理信息的。字符编码就是将符号转换为计算机能识别的二进制编码。
1.3. 两者的关系
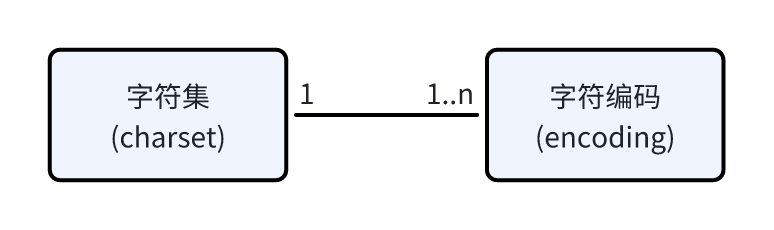
一般一个字符集等同于一种编码方式,如ASCII、GB2312、GBK等。一般我们说一种编码都是针对某一特定的字符集。
一个字符集上也可以有多种编码方式,如Unicode字符集有UTF-8、UTF-16、UTF-32等编码方式。所以字符集与字符编码是一对一或一对多的关系。
一句话表示:
字符集: 是要表达的所有字符的集合。字符编码: 是将字符集里每一个字符与二进制数据进行一一映射的的规则和机制。
2. 字符编码的发展历史
从计算机字符编码的发展历史来看,大概经历了三个阶段:
- 第一个阶段: ASCII编码
- 第二个阶段: 字符编码本地化——ANSI系列编码
- 第三个阶段: 字符编码国际化——Unicode字符集和Unicode编码
2.1. 第一个阶段 ASCII编码
第一个阶段:ASCII字符集和ASCII编码。
2.1.1. ASCII
计算机最早诞生于美国,刚开始计算机只支持英语(即拉丁字符),其它语言不能够在计算机上存储和显示。ASCII用一个字节(Byte)的7位(bit)表示一个字符,第一位(即最高位)置0,低7位用来编码字符集,共能表达2^7(即128)个字符。
ASCII的这种编码方式即为ASCII编码,ASCII编码的字符集即为ASCII字符集。ASCII字符集包含的内容有:26个小英文字母、26个大英文字母、英文标点符号,10个阿拉伯数字、以及非打印的(不能显示)控制符号。
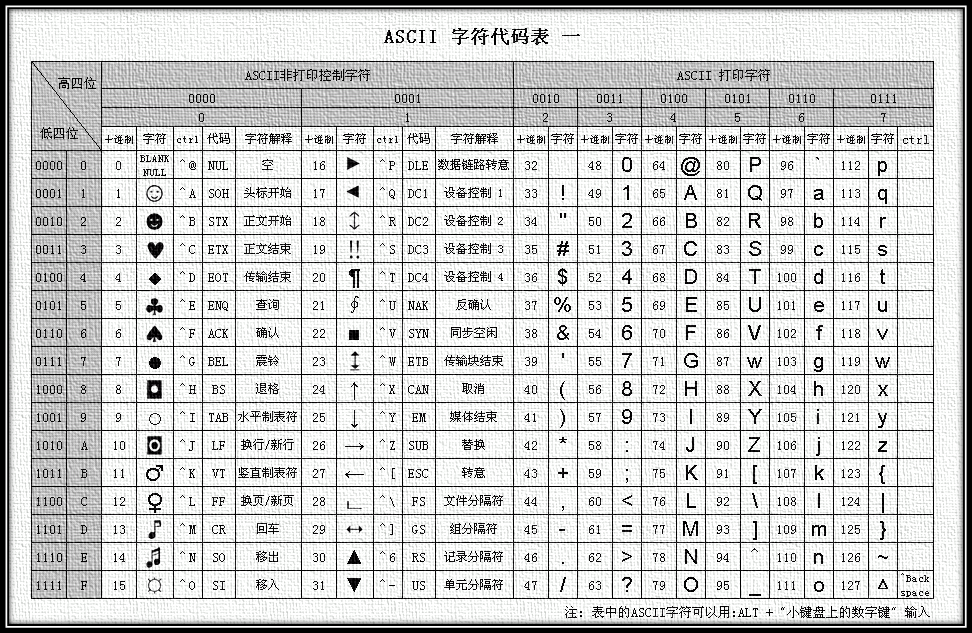
图1 ASCII编码表
2.1.2. EASCII
用ASCII码表达英语基本上没什么问题,但是当英语中包含一些外来词(如naïve、café、élite等)时,ASCII码就没有办法表达了,所有重音符号都不得不去掉。
后来为了表示更多的欧洲常用字符又对ASCII进行了扩展,于是有了EASCII(Extended ASCII),EASCII用8位表示一个字符,使它能多表示128个字符,支持了部分西欧字符。
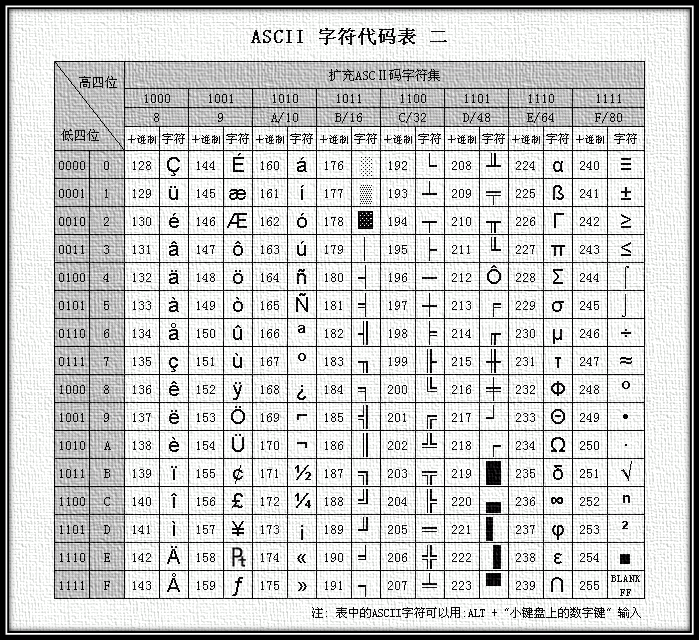
图2 扩展ASCII编码表
至此,ASCII + EASCII能表达256(2^8)个字符,基本能满足英语国家和欧洲部分国家的需求。
注意: EASCII码目前几乎不再使用了,很早就被废弃掉了,被更先进的ISO/IEC 8859-N字符编码方案替代了。
未完待续…… 欲知后事如何,请看下回分解。
下回预告:字符编码发展史2 — IOS 8859-N。
大家好,我是陌尘。
IT从业10年+, 北漂过也深漂过,目前暂定居于杭州,未来不知还会飘向何方。
搞了8年C++,也干过2年前端;用Python写过书,也玩过一点PHP,未来还会折腾更多东西,不死不休。
感谢大家的关注,期待与你一起成长。

1.本站内容仅供参考,不作为任何法律依据。用户在使用本站内容时,应自行判断其真实性、准确性和完整性,并承担相应风险。
2.本站部分内容来源于互联网,仅用于交流学习研究知识,若侵犯了您的合法权益,请及时邮件或站内私信与本站联系,我们将尽快予以处理。
3.本文采用知识共享 署名4.0国际许可协议 [BY-NC-SA] 进行授权
4.根据《计算机软件保护条例》第十七条规定“为了学习和研究软件内含的设计思想和原理,通过安装、显示、传输或者存储软件等方式使用软件的,可以不经软件著作权人许可,不向其支付报酬。”您需知晓本站所有内容资源均来源于网络,仅供用户交流学习与研究使用,版权归属原版权方所有,版权争议与本站无关,用户本人下载后不能用作商业或非法用途,需在24个小时之内从您的电脑中彻底删除上述内容,否则后果均由用户承担责任;如果您访问和下载此文件,表示您同意只将此文件用于参考、学习而非其他用途,否则一切后果请您自行承担,如果您喜欢该程序,请支持正版软件,购买注册,得到更好的正版服务。
5.本站是非经营性个人站点,所有软件信息均来自网络,所有资源仅供学习参考研究目的,并不贩卖软件,不存在任何商业目的及用途







暂无评论内容