
UMICH CV Linear Classifiers
在上一篇博文中,我们讨论了利用损失函数来判断一个权重矩阵的好坏,在这节中我们将讨论如何去找到最优的权重矩阵
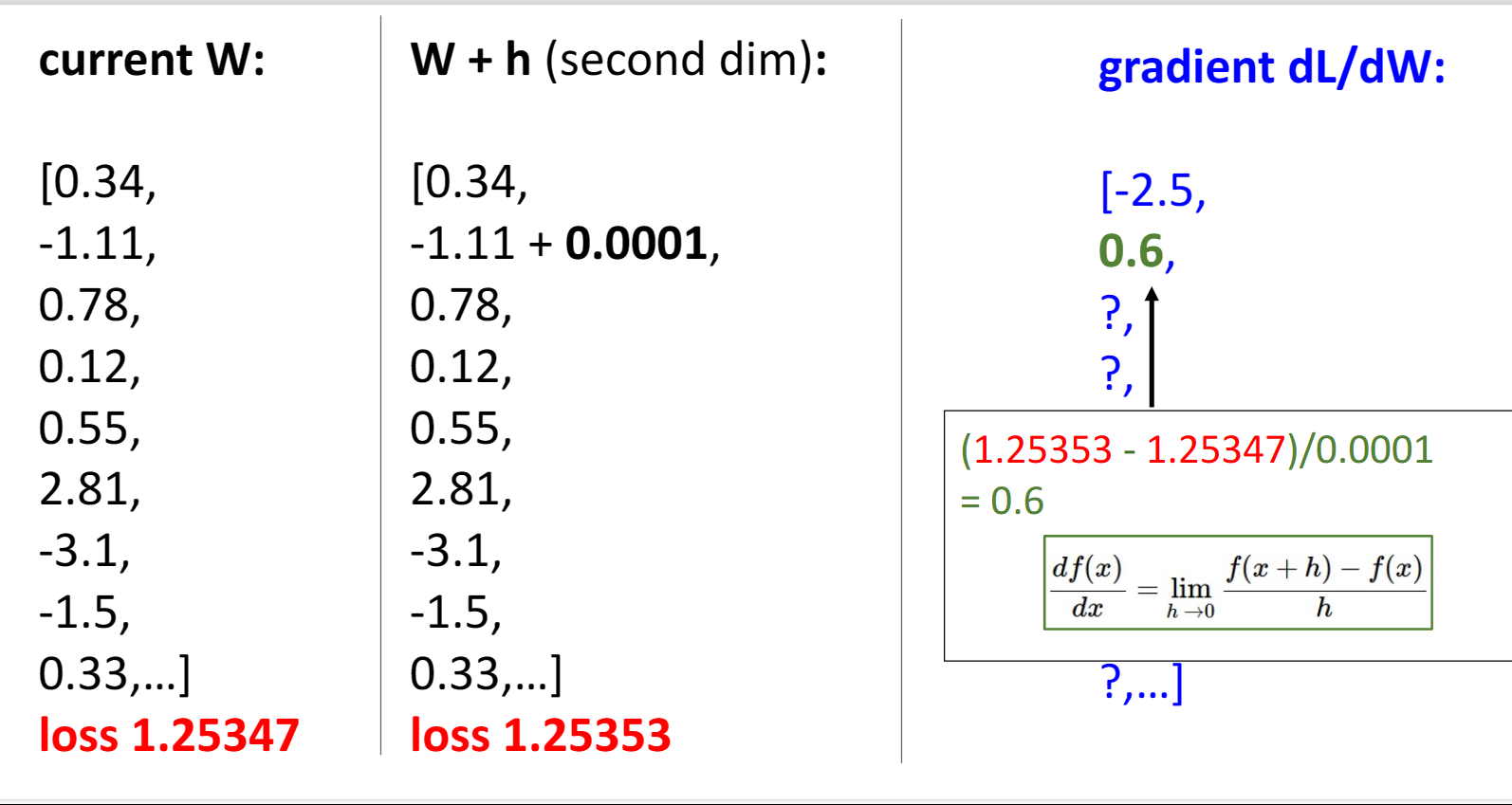
想象我们要下到一个峡谷的底部,我们自然会选择下降最快的斜坡,换成我们这个问题就是要求权重矩阵相对于损失函数的梯度函数,最简单的方法就是使用定义法:
![图片[1]-umich cv-2-2 - 玄机博客-玄机博客](https://img2023.cnblogs.com/blog/3261639/202310/3261639-20231006203308546-1697843359.png)
我们也可以使用解析梯度,这里需要用到矩阵对向量,矩阵对标量求导的一些知识,在后面我们也会采用反向传播的方法,因为自己手算微积分毕竟比较容易出错,尤其是涉及到很多层神经网络的时候。
在作业assignment2 的第一个线性分类器的实现中,我们会使用两张种损失函数,分别是svm与softmax函数,需要我们使用解析梯度来计算,这里推荐两篇博文的推导过程,因为我这边基础也不是很好,需要再深入学习一下
svm:http://giantpandacv.com/academic/算法科普/深度学习基础/SVM Loss以及梯度推导/
softmax:https://blog.csdn.net/qq_27261889/article/details/82915598
计算得到梯度函数之后,我们就可以让loss沿着梯度的方向下降:
![图片[2]-umich cv-2-2 - 玄机博客-玄机博客](https://img2023.cnblogs.com/blog/3261639/202310/3261639-20231006204339649-1590011719.png)
这里有三个超参数,是我们自己手动设置的,分别是权重矩阵初始化的策略,迭代步骤与学习率
但是对所有的样本都进行梯度下降,显然是非常耗时的一件事,所以我们一般采用sgd方法,也就是随机梯度下降:
![图片[3]-umich cv-2-2 - 玄机博客-玄机博客](https://img2023.cnblogs.com/blog/3261639/202310/3261639-20231006204527028-63720841.png)
这里又多了batch size与抽样方法两个超参数
但是SGD的缺点在于会导致梯度剧烈波动,有的地方下降很快有的地方下降很慢,同时也面临着陷入局部最优解的困境,所以出现了SGD + Momentum
![图片[4]-umich cv-2-2 - 玄机博客-玄机博客](https://img2023.cnblogs.com/blog/3261639/202310/3261639-20231006205110878-879365839.png)
![图片[5]-umich cv-2-2 - 玄机博客-玄机博客](https://img2023.cnblogs.com/blog/3261639/202310/3261639-20231006205303455-824662383.png)
加入一个速度变量这样在下降快的时候可以抑制梯度的下降,起到一个平衡作用
Momentum也有变体 Nesterov Momentum,与Momentum唯一区别就是,计算梯度的不同。Nesterov动量中,先用当前的速 v临时更新一遍参数,在用更新的临时参数计算梯度,就是一种向前看的思想:
![图片[6]-umich cv-2-2 - 玄机博客-玄机博客](https://img2023.cnblogs.com/blog/3261639/202310/3261639-20231006210134557-2147035482.png)

另一类进行优化的方法采用dw的平方
Adagrad 与 Rmsprop
![图片[7]-umich cv-2-2 - 玄机博客-玄机博客](https://img2023.cnblogs.com/blog/3261639/202310/3261639-20231006210456201-1665779639.png)
由于adagrad会导致下降的过快,因为有平方的存在,所以又提出了RMSProp,加入decay_rate来放缓下降速度
最常用的优化方法就是adam
![图片[8]-umich cv-2-2 - 玄机博客-玄机博客](https://img2023.cnblogs.com/blog/3261639/202310/3261639-20231006212241452-438296596.png)
注意这里要加入偏差修正项防止起始的时候误差太大
这里有一篇知乎的回答可供参考:https://www.zhihu.com/question/323747423
上面的方法都是采用一阶导数:
![图片[9]-umich cv-2-2 - 玄机博客-玄机博客](https://img2023.cnblogs.com/blog/3261639/202310/3261639-20231006212653133-92630411.png)
有时候我们也可以采用二阶导数
![图片[10]-umich cv-2-2 - 玄机博客-玄机博客](https://img2023.cnblogs.com/blog/3261639/202310/3261639-20231006212753514-1417749457.png)
但是二阶导的计算可想而知的复杂,所以我们一般很少采用二阶导进行优化
最后是一些二阶导的讨论:
![图片[11]-umich cv-2-2 - 玄机博客-玄机博客](https://img2023.cnblogs.com/blog/3261639/202310/3261639-20231006213012043-743219396.png)
![图片[12]-umich cv-2-2 - 玄机博客-玄机博客](https://img2023.cnblogs.com/blog/3261639/202310/3261639-20231006213021974-1932332194.png)

本次assignment A2 的第一个线性分类器 主要内容就是分别采用svm与softmax损失函数进行优化计算,也没有用到后面复杂的优化方法,就是最简单的学习率乘以dw,比较复杂的就是解析梯度的推导,可参考上面的两篇博文
1.本站内容仅供参考,不作为任何法律依据。用户在使用本站内容时,应自行判断其真实性、准确性和完整性,并承担相应风险。
2.本站部分内容来源于互联网,仅用于交流学习研究知识,若侵犯了您的合法权益,请及时邮件或站内私信与本站联系,我们将尽快予以处理。
3.本文采用知识共享 署名4.0国际许可协议 [BY-NC-SA] 进行授权
4.根据《计算机软件保护条例》第十七条规定“为了学习和研究软件内含的设计思想和原理,通过安装、显示、传输或者存储软件等方式使用软件的,可以不经软件著作权人许可,不向其支付报酬。”您需知晓本站所有内容资源均来源于网络,仅供用户交流学习与研究使用,版权归属原版权方所有,版权争议与本站无关,用户本人下载后不能用作商业或非法用途,需在24个小时之内从您的电脑中彻底删除上述内容,否则后果均由用户承担责任;如果您访问和下载此文件,表示您同意只将此文件用于参考、学习而非其他用途,否则一切后果请您自行承担,如果您喜欢该程序,请支持正版软件,购买注册,得到更好的正版服务。
5.本站是非经营性个人站点,所有软件信息均来自网络,所有资源仅供学习参考研究目的,并不贩卖软件,不存在任何商业目的及用途












暂无评论内容