

-
本工具设计的初衷是用来获取微信账号的相关信息并解析PC版微信的数据库。
-
程序以 Python 语言开发,可读取、解密、还原微信数据库并帮助用户查看聊天记录,还可以将其聊天记录导出为csv、html等格式用于AI训练,自动回复或备份等等作用。下面我们将深入探讨这个工具的各个方面及其工作原理。
-
本项目仅供学习交流使用,严禁用于商业用途或非法途径,任何违反法律法规、侵犯他人合法权益的行为,均与本项目及其开发者无关,后果由行为人自行承担。
【完整演示工具下载】
https://www.chwm.vip/index.html?aid=23
我们接着上一篇文章《劫持微信聊天记录并分析还原 —— 解密数据库(二)》将解密后的微信数据库合并为一整个DB文件。
微信数据库存放目录:
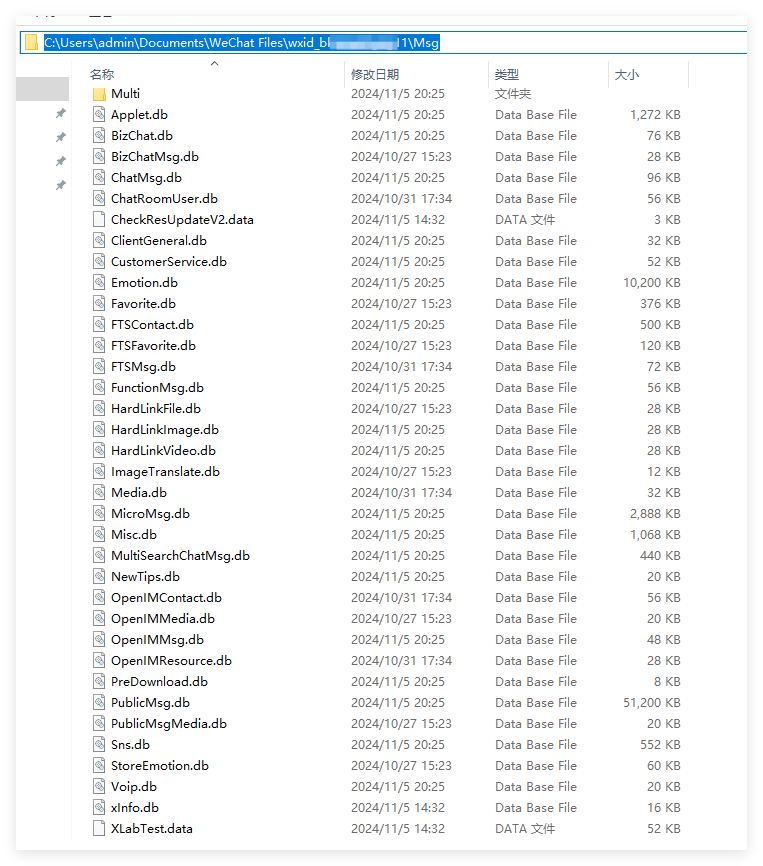
解密后的微信数据库:
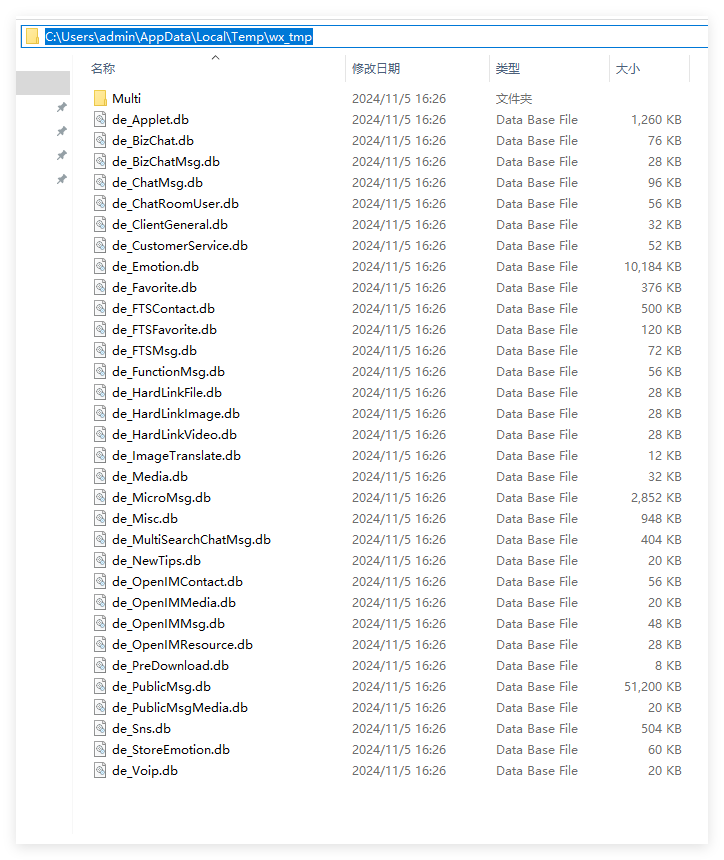
详细命令:
merge -i "C:UsersadminAppDataLocalTempwx_tmp" -o "C:UsersadminAppDataLocalTempwxdb_all.db"
- -i 为解密后微信数据库的存放路径
- -o 为合并微信数据库的存放路径与文件名
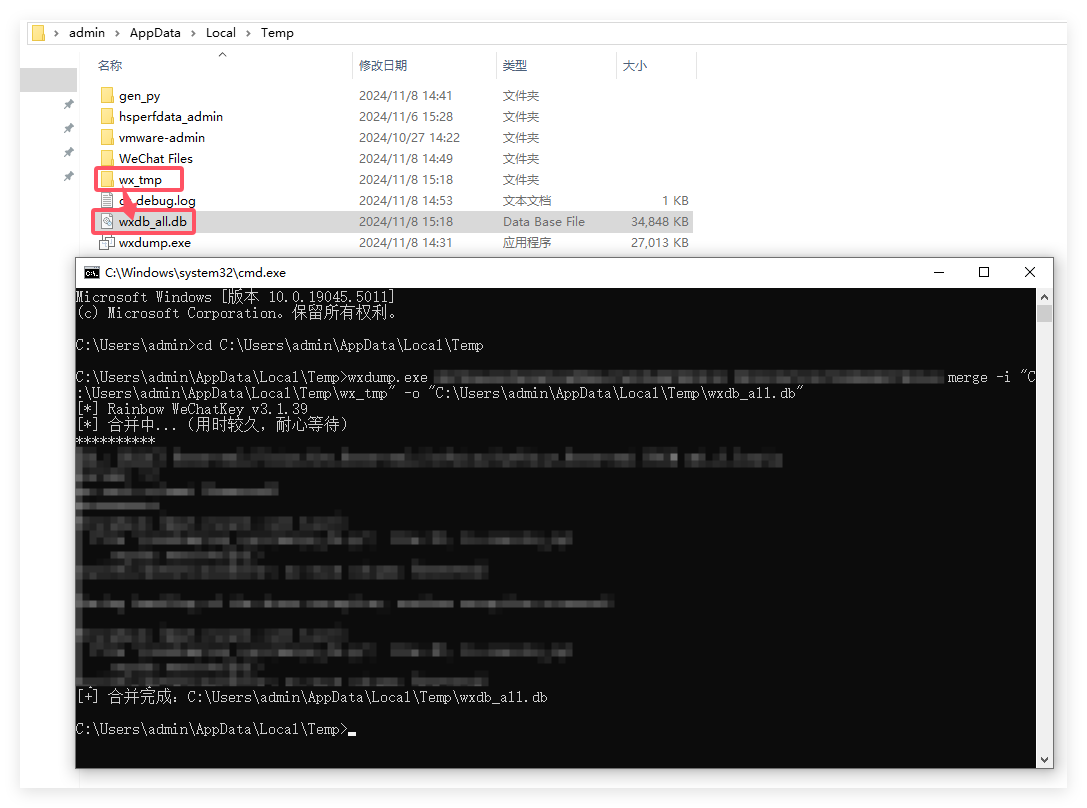
运行命令后,我们可以看到在此位置 “C:UsersadminAppDataLocalTemp” 下生成了一个以 “wxdb_all.db” 命名的文件,这便是解密后的微信数据库合并成功的文件,下一步我们将详细解读微信数据库的结构以及如何打开并访问里面的内容。
部分现实代码:
# -*- coding: utf-8 -*-#
# -------------------------------------------------------------------------------
# Name: merge_db.py
# Description:
# Author: Rainbow(www.chwm.vip)
# Date: 2024/11/08
# -------------------------------------------------------------------------------
import logging
import os
import shutil
import sqlite3
import subprocess
import time
from typing import List
from .decryption import batch_decrypt
from .wx_info import get_core_db
from .utils import wx_core_loger, wx_core_error, CORE_DB_TYPE
@wx_core_error
def execute_sql(connection, sql, params=None):
"""
执行给定的SQL语句,返回结果。
参数:
- connection: SQLite连接
- sql:要执行的SQL语句
- params:SQL语句中的参数
"""
try:
# connection.text_factory = bytes
cursor = connection.cursor()
if params:
cursor.execute(sql, params)
else:
cursor.execute(sql)
return cursor.fetchall()
except Exception as e:
try:
connection.text_factory = bytes
cursor = connection.cursor()
if params:
cursor.execute(sql, params)
else:
cursor.execute(sql)
rdata = cursor.fetchall()
connection.text_factory = str
return rdata
except Exception as e:
wx_core_loger.error(f"**********nSQL: {sql}nparams: {params}n{e}n**********", exc_info=True)
return None
@wx_core_error
def check_create_sync_log(connection):
"""
检查是否存在表 sync_log,用于记录同步记录,包括微信数据库路径,表名,记录数,同步时间
:param connection: SQLite连接
:return: True or False
"""
out_cursor = connection.cursor()
# 检查是否存在表 sync_log,用于记录同步记录,包括微信数据库路径,表名,记录数,同步时间
sync_log_status = execute_sql(connection, "SELECT name FROM sqlite_master WHERE type='table' AND name='sync_log'")
if len(sync_log_status) < 1:
# db_path 微信数据库路径,tbl_name 表名,src_count 源数据库记录数,current_count 当前合并后的数据库对应表记录数
sync_record_create_sql = ("CREATE TABLE sync_log ("
"id INTEGER PRIMARY KEY AUTOINCREMENT,"
"db_path TEXT NOT NULL,"
"tbl_name TEXT NOT NULL,"
"src_count INT,"
"current_count INT,"
"createTime INT DEFAULT (strftime('%s', 'now')), "
"updateTime INT DEFAULT (strftime('%s', 'now'))"
");")
out_cursor.execute(sync_record_create_sql)
# 创建索引
out_cursor.execute("CREATE INDEX idx_sync_log_db_path ON sync_log (db_path);")
out_cursor.execute("CREATE INDEX idx_sync_log_tbl_name ON sync_log (tbl_name);")
# 创建联合索引,防止重复
out_cursor.execute("CREATE UNIQUE INDEX idx_sync_log_db_tbl ON sync_log (db_path, tbl_name);")
connection.commit()
out_cursor.close()
return True
@wx_core_error
def check_create_file_md5(connection):
"""
检查是否存在表 file_md5,用于记录文件信息,后续用于去重等操作,暂时闲置
"""
pass
@wx_core_error
def merge_db(db_paths: List[dict], save_path: str = "merge.db", is_merge_data: bool = True,
startCreateTime: int = 0, endCreateTime: int = 0):
"""
合并数据库 会忽略主键以及重复的行。
:param db_paths: [{"db_path": "xxx", "de_path": "xxx"},...]
db_path表示初始路径,de_path表示解密后的路径;初始路径用于保存合并的日志情况,解密后的路径用于读取数据
:param save_path: str 输出文件路径
:param is_merge_data: bool 是否合并数据(如果为False,则只解密,并创建表,不插入数据)
:param startCreateTime: 开始时间戳 主要用于MSG数据库的合并
:param endCreateTime: 结束时间戳 主要用于MSG数据库的合并
:return:
"""
if os.path.isdir(save_path):
save_path = os.path.join(save_path, f"merge_{int(time.time())}.db")
if isinstance(db_paths, list):
# alias, file_path
databases = {f"dbi_{i}": (db['db_path'],
db.get('de_path', db['db_path'])
) for i, db in enumerate(db_paths)
}
else:
raise TypeError("db_paths 类型错误")
outdb = sqlite3.connect(save_path)
is_sync_log = check_create_sync_log(outdb)
if not is_sync_log:
wx_core_loger.warning("创建同步记录表失败")
out_cursor = outdb.cursor()
# 将MSG_db_paths中的数据合并到out_db_path中
for alias, db in databases.items():
db_path = db[0]
de_path = db[1]
# 附加数据库
sql_attach = f"ATTACH DATABASE '{de_path}' AS {alias}"
out_cursor.execute(sql_attach)
outdb.commit()
sql_query_tbl_name = f"SELECT tbl_name, sql FROM {alias}.sqlite_master WHERE type='table' ORDER BY tbl_name;"
tables = execute_sql(outdb, sql_query_tbl_name)
for table in tables:
table, init_create_sql = table[0], table[1]
table = table if isinstance(table, str) else table.decode()
init_create_sql = init_create_sql if isinstance(init_create_sql, str) else init_create_sql.decode()
if table == "sqlite_sequence":
continue
if "CREATE TABLE".lower() not in str(init_create_sql).lower():
continue
# 获取表中的字段名
sql_query_columns = f"PRAGMA table_info({table})"
columns = execute_sql(outdb, sql_query_columns)
if table == "ChatInfo" and len(columns) > 12: # bizChat中的ChatInfo表与MicroMsg中的ChatInfo表字段不同
continue
col_type = {
(i[1] if isinstance(i[1], str) else i[1].decode(),
i[2] if isinstance(i[2], str) else i[2].decode())
for i in columns}
columns = [i[0] for i in col_type]
if not columns or len(columns) < 1:
continue
# 创建表table
sql_create_tbl = f"CREATE TABLE IF NOT EXISTS {table} AS SELECT * FROM {alias}.{table} WHERE 0 = 1;"
out_cursor.execute(sql_create_tbl)
# 创建包含 NULL 值比较的 UNIQUE 索引
index_name = f"{table}_unique_index"
coalesce_columns = ','.join(f"COALESCE({column}, '')" for column in columns)
sql = f"CREATE UNIQUE INDEX IF NOT EXISTS {index_name} ON {table} ({coalesce_columns})"
out_cursor.execute(sql)
# 插入sync_log
sql_query_sync_log = f"SELECT src_count FROM sync_log WHERE db_path=? AND tbl_name=?"
sync_log = execute_sql(outdb, sql_query_sync_log, (db_path, table))
if not sync_log or len(sync_log) < 1:
sql_insert_sync_log = "INSERT INTO sync_log (db_path, tbl_name, src_count, current_count) VALUES (?, ?, ?, ?)"
out_cursor.execute(sql_insert_sync_log, (db_path, table, 0, 0))
outdb.commit()
if is_merge_data:
# 比较源数据库和合并后的数据库记录数
log_src_count = execute_sql(outdb, sql_query_sync_log, (db_path, table))[0][0]
src_count = execute_sql(outdb, f"SELECT COUNT(*) FROM {alias}.{table}")[0][0]
if src_count <= log_src_count:
wx_core_loger.info(f"忽略 {db_path} {de_path} {table} {src_count} {log_src_count}")
continue
# 构建数据查询sql
sql_base = f"SELECT {','.join([i for i in columns])} FROM {alias}.{table} "
where_clauses, params = [], []
if "CreateTime" in columns:
if startCreateTime > 0:
where_clauses.append("CreateTime > ?")
params.append(startCreateTime)
if endCreateTime > 0:
where_clauses.append("CreateTime < ?")
params.append(endCreateTime)
# 如果有WHERE子句,将其添加到SQL语句中,并添加ORDER BY子句
sql = f"{sql_base} WHERE {' AND '.join(where_clauses)} ORDER BY CreateTime" if where_clauses else sql_base
src_data = execute_sql(outdb, sql, tuple(params))
if not src_data or len(src_data) < 1:
continue
# 插入数据
sql = f"INSERT OR IGNORE INTO {table} ({','.join([i for i in columns])}) VALUES ({','.join(['?'] * len(columns))})"
try:
out_cursor.executemany(sql, src_data)
# update sync_log
sql_update_sync_log = ("UPDATE sync_log "
"SET src_count = ? ,"
f"current_count=(SELECT COUNT(*) FROM {table}) "
"WHERE db_path=? AND tbl_name=?")
out_cursor.execute(sql_update_sync_log, (src_count, db_path, table))
except Exception as e:
wx_core_loger.error(
f"error: {db_path}n{de_path}n{table}n{sql}n{src_data}n{len(src_data)}n{e}n",
exc_info=True)
# 分离数据库
sql_detach = f"DETACH DATABASE {alias}"
out_cursor.execute(sql_detach)
outdb.commit()
out_cursor.close()
outdb.close()
return save_path
# @wx_core_error
# def merge_db1(db_paths: list[dict], save_path: str = "merge.db", is_merge_data: bool = True,
# startCreateTime: int = 0, endCreateTime: int = 0):
# """
# 合并数据库 会忽略主键以及重复的行。
# :param db_paths: [{"db_path": "xxx", "de_path": "xxx"},...]
# db_path表示初始路径,de_path表示解密后的路径;初始路径用于保存合并的日志情况,解密后的路径用于读取数据
# :param save_path: str 输出文件路径
# :param is_merge_data: bool 是否合并数据(如果为False,则只解密,并创建表,不插入数据)
# :param startCreateTime: 开始时间戳 主要用于MSG数据库的合并
# :param endCreateTime: 结束时间戳 主要用于MSG数据库的合并
# :return:
# """
# if os.path.isdir(save_path):
# save_path = os.path.join(save_path, f"merge_{int(time.time())}.db")
#
# if isinstance(db_paths, list):
# # alias, file_path
# databases = {f"MSG{i}": (db['db_path'],
# db.get('de_path', db['db_path'])
# ) for i, db in enumerate(db_paths)
# }
# else:
# raise TypeError("db_paths 类型错误")
#
# from sqlalchemy import create_engine, MetaData, Table, select, insert, Column, UniqueConstraint
# from sqlalchemy.orm import sessionmaker
# from sqlalchemy import inspect, PrimaryKeyConstraint
#
# outdb = create_engine(f"sqlite:///{save_path}", echo=False)
#
# # 创建Session实例
# Session = sessionmaker()
# Session.configure(bind=outdb)
# session = Session()
#
# # 将MSG_db_paths中的数据合并到out_db_path中
# for alias, db in databases.items():
# db_path = db[0]
# de_path = db[1]
#
# db_engine = create_engine(f"sqlite:///{de_path}", echo=False)
#
# # 反射源数据库的表结构
# metadata = MetaData()
# metadata.reflect(bind=db_engine)
#
# # 创建表
# outdb_metadata = MetaData()
# inspector = inspect(db_engine)
# table_names = [i for i in inspector.get_table_names() if i not in ["sqlite_sequence"]]
# for table_name in table_names:
# # 创建表table
# columns_list_dict = inspector.get_columns(table_name)
# col_names = [i['name'] for i in columns_list_dict]
# columns = [Column(i['name'], i['type'], primary_key=False) for i in columns_list_dict]
# table = Table(table_name, outdb_metadata, *columns)
# if len(columns) > 1: # 联合索引
# unique_constraint = UniqueConstraint(*col_names, name=f"{table_name}_unique_index")
# table.append_constraint(unique_constraint)
# else:
# table.append_constraint(PrimaryKeyConstraint(*col_names))
# table.create(outdb, checkfirst=True)
#
# # 将源数据库中的数据插入目标数据库
# outdb_metadata = MetaData()
# for table_name in metadata.tables:
# source_table = Table(table_name, metadata, autoload_with=db_engine)
# outdb_table = Table(table_name, outdb_metadata, autoload_with=outdb)
#
# # 查询源表中的所有数据
# query = select(source_table)
# with db_engine.connect() as connection:
# result = connection.execute(query).fetchall()
#
# # 插入到目标表中
# for row in result:
# row_data = row._asdict()
#
# # 尝试将所有文本数据转换为 UTF-8
# for key, value in row_data.items():
# if isinstance(value, str):
# row_data[key] = value.encode("utf-8")
#
# insert_stmt = insert(outdb_table).values(row_data)
# try:
# session.execute(insert_stmt)
# except Exception as e:
# pass
# db_engine.dispose()
#
# # 提交事务
# session.commit()
# # 关闭Session
# session.close()
# outdb.dispose()
# return save_path
@wx_core_error
def decrypt_merge(wx_path: str, key: str, outpath: str = "",
merge_save_path: str = None,
is_merge_data=True, is_del_decrypted: bool = True,
startCreateTime: int = 0, endCreateTime: int = 0,
db_type=None) -> (bool, str):
"""
解密合并数据库 msg.db, microMsg.db, media.db,注意:会删除原数据库
:param wx_path: 微信路径 eg: C:\*******\WeChat Files\wxid_*********
:param key: 解密密钥
:param outpath: 输出路径
:param merge_save_path: 合并后的数据库路径
:param is_merge_data: 是否合并数据(如果为False,则只解密,并创建表,不插入数据)
:param is_del_decrypted: 是否删除解密后的数据库(除了合并后的数据库)
:param startCreateTime: 开始时间戳 主要用于MSG数据库的合并
:param endCreateTime: 结束时间戳 主要用于MSG数据库的合并
:param db_type: 数据库类型,从核心数据库中选择
:return: (true,解密后的数据库路径) or (false,错误信息)
"""
if db_type is None:
db_type = []
outpath = outpath if outpath else "decrypt_merge_tmp"
merge_save_path = os.path.join(outpath,
f"merge_{int(time.time())}.db") if merge_save_path is None else merge_save_path
decrypted_path = os.path.join(outpath, "decrypted")
if not wx_path or not key or not os.path.exists(wx_path):
wx_core_loger.error("参数错误", exc_info=True)
return False, "参数错误"
# 解密
code, wxdbpaths = get_core_db(wx_path, db_type)
if not code:
wx_core_loger.error(f"获取数据库路径失败{wxdbpaths}", exc_info=True)
return False, wxdbpaths
# 判断out_path是否为空目录
if os.path.exists(decrypted_path) and os.listdir(decrypted_path):
for root, dirs, files in os.walk(decrypted_path, topdown=False):
for name in files:
os.remove(os.path.join(root, name))
for name in dirs:
os.rmdir(os.path.join(root, name))
if not os.path.exists(decrypted_path):
os.makedirs(decrypted_path)
wxdbpaths = {i["db_path"]: i for i in wxdbpaths}
# 调用 decrypt 函数,并传入参数 # 解密
code, ret = batch_decrypt(key=key, db_path=list(wxdbpaths.keys()), out_path=decrypted_path, is_print=False)
if not code:
wx_core_loger.error(f"解密失败{ret}", exc_info=True)
return False, ret
out_dbs = []
for code1, ret1 in ret:
if code1:
out_dbs.append(ret1)
parpare_merge_db_path = []
for db_path, out_path, _ in out_dbs:
parpare_merge_db_path.append({"db_path": db_path, "de_path": out_path})
merge_save_path = merge_db(parpare_merge_db_path, merge_save_path, is_merge_data=is_merge_data,
startCreateTime=startCreateTime, endCreateTime=endCreateTime)
if is_del_decrypted:
shutil.rmtree(decrypted_path, True)
if isinstance(merge_save_path, str):
return True, merge_save_path
else:
return False, "未知错误"
@wx_core_error
def merge_real_time_db(key, merge_path: str, db_paths: [dict] or dict, real_time_exe_path: str = None):
"""
合并实时数据库消息,暂时只支持64位系统
:param key: 解密密钥
:param merge_path: 合并后的数据库路径
:param db_paths: [dict] or dict eg: {'wxid': 'wxid_***', 'db_type': 'MicroMsg',
'db_path': 'C:**wxid_***MsgMicroMsg.db', 'wxid_dir': 'C:***wxid_***'}
:param real_time_exe_path: 实时数据库合并工具路径
:return:
"""
try:
import platform
except:
raise ImportError("未找到模块 platform")
# 判断系统位数是否为64位,如果不是则抛出异常
if platform.architecture()[0] != '64bit':
raise Exception("System is not 64-bit.")
if isinstance(db_paths, dict):
db_paths = [db_paths]
merge_path = os.path.abspath(merge_path) # 合并后的数据库路径,必须为绝对路径
merge_path_base = os.path.dirname(merge_path) # 合并后的数据库路径
if not os.path.exists(merge_path_base):
os.makedirs(merge_path_base)
endbs = []
for db_info in db_paths:
db_path = os.path.abspath(db_info['db_path'])
if not os.path.exists(db_path):
# raise FileNotFoundError("数据库不存在")
continue
endbs.append(os.path.abspath(db_path))
endbs = '" "'.join(list(set(endbs)))
if not os.path.exists(real_time_exe_path if real_time_exe_path else ""):
current_path = os.path.dirname(__file__) # 获取当前文件夹路径
real_time_exe_path = os.path.join(current_path, "tools", "realTime.exe")
if not os.path.exists(real_time_exe_path):
raise FileNotFoundError("未找到实时数据库合并工具")
real_time_exe_path = os.path.abspath(real_time_exe_path)
# 调用cmd命令
cmd = f'{real_time_exe_path} "{key}" "{merge_path}" "{endbs}"'
# os.system(cmd)
# wx_core_loger.info(f"合并实时数据库命令:{cmd}")
p = subprocess.Popen(cmd, shell=False, stdout=subprocess.PIPE, stderr=subprocess.PIPE, cwd=merge_path_base,
creationflags=subprocess.CREATE_NO_WINDOW)
out, err = p.communicate() # 查看返回值
if out and out.decode("utf-8").find("SUCCESS") >= 0:
wx_core_loger.info(f"合并实时数据库成功{out}")
return True, merge_path
else:
wx_core_loger.error(f"合并实时数据库失败n{out}n{err}")
return False, (out, err)
@wx_core_error
def all_merge_real_time_db(key, wx_path, merge_path: str, real_time_exe_path: str = None):
"""
合并所有实时数据库
注:这是全量合并,会有可能产生重复数据,需要自行去重
:param key: 解密密钥
:param wx_path: 微信文件夹路径 eg:C:*****WeChat Fileswxid*******
:param merge_path: 合并后的数据库路径 eg: C:\*******\WeChat Files\wxid_*********\merge.db
:param real_time_exe_path: 实时数据库合并工具路径
:return:
"""
if not merge_path or not key or not wx_path or not wx_path:
return False, "msg_path or media_path or wx_path or key is required"
try:
from wxdump import get_core_db
except ImportError:
return False, "未找到模块 wxdump"
db_paths = get_core_db(wx_path, CORE_DB_TYPE)
if not db_paths[0]:
return False, db_paths[1]
db_paths = db_paths[1]
code, ret = merge_real_time_db(key=key, merge_path=merge_path, db_paths=db_paths,
real_time_exe_path=real_time_exe_path)
if code:
return True, merge_path
else:
return False, ret
1.本站内容仅供参考,不作为任何法律依据。用户在使用本站内容时,应自行判断其真实性、准确性和完整性,并承担相应风险。
2.本站部分内容来源于互联网,仅用于交流学习研究知识,若侵犯了您的合法权益,请及时邮件或站内私信与本站联系,我们将尽快予以处理。
3.本文采用知识共享 署名4.0国际许可协议 [BY-NC-SA] 进行授权
4.根据《计算机软件保护条例》第十七条规定“为了学习和研究软件内含的设计思想和原理,通过安装、显示、传输或者存储软件等方式使用软件的,可以不经软件著作权人许可,不向其支付报酬。”您需知晓本站所有内容资源均来源于网络,仅供用户交流学习与研究使用,版权归属原版权方所有,版权争议与本站无关,用户本人下载后不能用作商业或非法用途,需在24个小时之内从您的电脑中彻底删除上述内容,否则后果均由用户承担责任;如果您访问和下载此文件,表示您同意只将此文件用于参考、学习而非其他用途,否则一切后果请您自行承担,如果您喜欢该程序,请支持正版软件,购买注册,得到更好的正版服务。
5.本站是非经营性个人站点,所有软件信息均来自网络,所有资源仅供学习参考研究目的,并不贩卖软件,不存在任何商业目的及用途




暂无评论内容