
0 前言
- 本文主要介绍决策树ID3算法,并举出构建示例帮助理解。
- 读者需要具备的知识:信息熵、条件熵、信息增益。
- 本文使用数据集为:游玩数据集 1.1节、西瓜数据集 1.2节。
1 ID3算法简述
ID3(Iterative Dichotomiser 3)算法是一种经典的决策树学习算法,由Ross Quinlan于1986年提出。该算法的主要目的是通过构建一个决策树模型来对样本数据进行分类。ID3算法的核心思想是基于信息增益(Information Gain)来选择最佳的属性作为决策树的节点,以此来实现对数据的划分。
2 算法流程
-
初始化:首先,算法将所有训练样本集放在根节点。
-
特征选择:对于当前节点,计算所有候选特征的信息增益。选择信息增益最大的特征作为当前节点的分裂特征。
-
节点分裂:根据所选特征的每个不同取值,将当前节点划分为多个子节点。每个子节点包含该特征取值下对应的所有样本。
-
递归构建:对于每个子节点,递归地执行步骤2和步骤3,直到满足停止条件(如所有样本属于同一类别、没有更多特征可供选择等)。
-
构建完成:最终,当所有节点都无法再进一步划分时,决策树构建完成。
注:ID3算法需要设定特征集阈值ε,设置阈值的主要作用是限制决策树的深度、防止过拟合、平衡模型复杂度和泛化能力。当最大信息增益小于阈值ε时,则设置为单节点,不进行分支,反之则递归地执行步骤2和步骤3。本文未考虑设置阈值。
3 例题一
-
数据集采用游玩数据集,由于样本数据较简单,例题并没有考虑设置阈值。
-
初始化,构建根节点。具体构建方法如下图(3-1)所示。
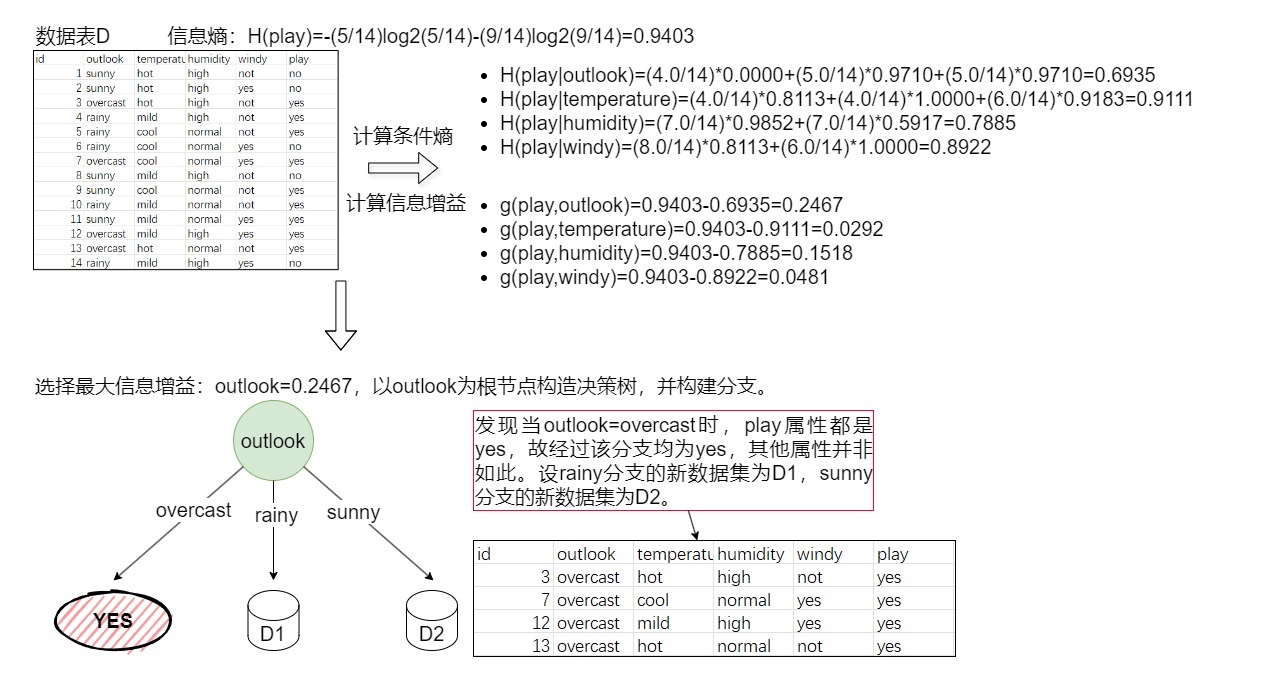
解释:计算出随机变量play的信息熵H(play),再计算出每个特征的条件熵,得出每个特征的信息增益,选择最大的信息增益对应的属性为根节点,然后对根节点分裂,出现3条子枝。 -
递归构建,构建图3-1的D1。具体构建方法如下图(3-2)所示。
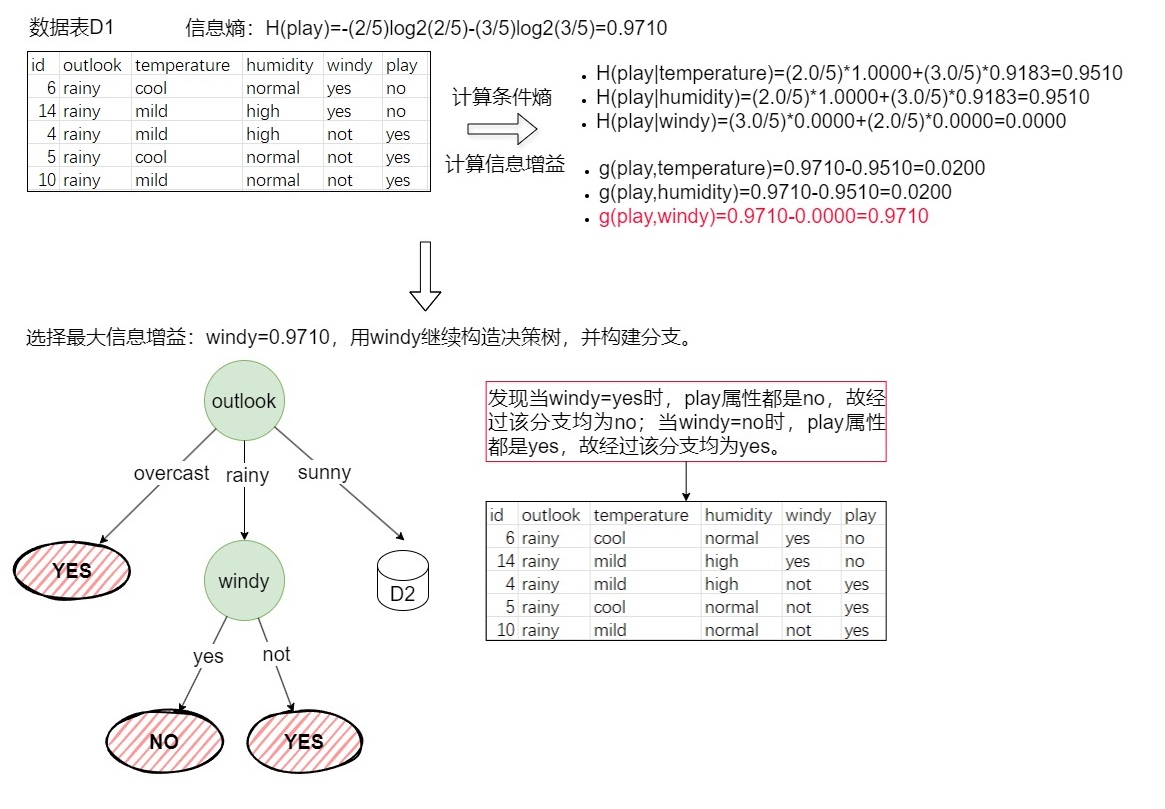
解释:上图是构建图3-1的D1,由于图3-1的D1表示的是数据集D在outlook=rainy的条件下的新数据集,D1数据集中的outlook属性都是rainy,故不需要再计算g(play,outlook)。 -
递归构建,构建图3-2的D2。具体构建方法如下图(3-3)所示。
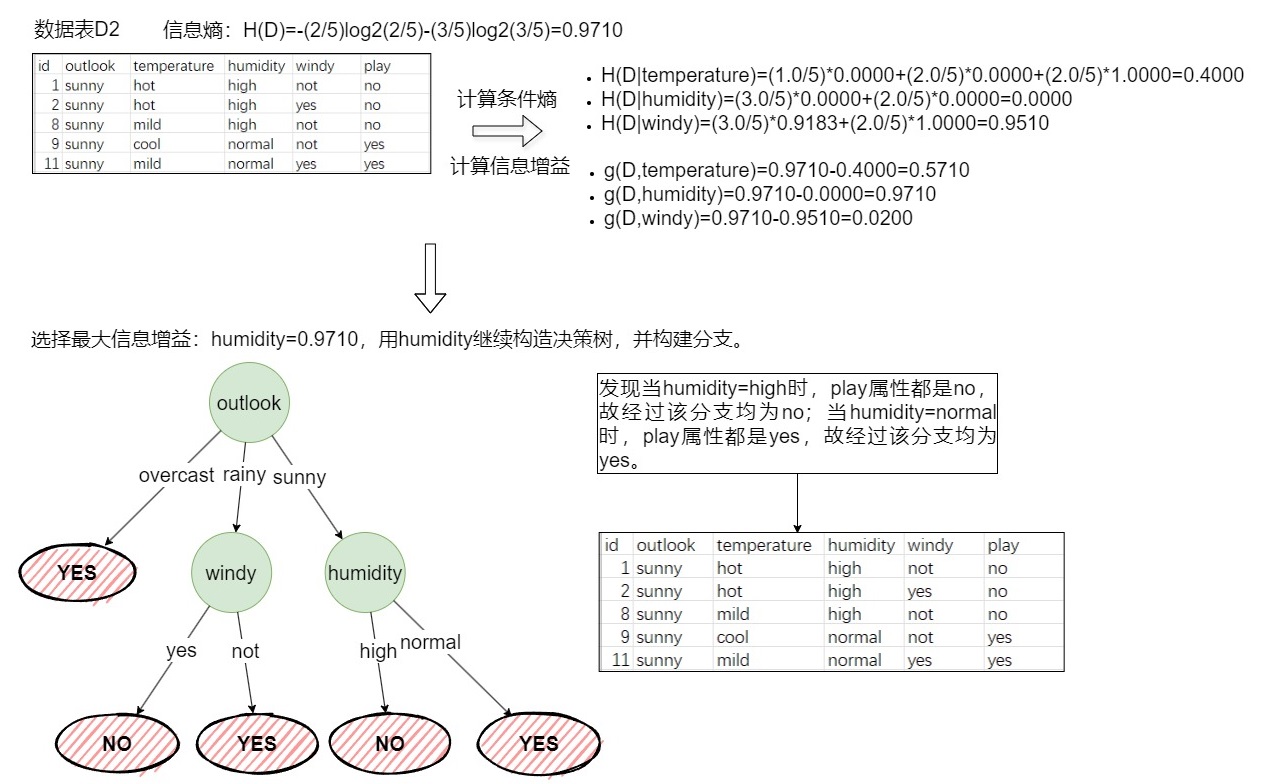
解释:图3-3的windy节点构建完毕,递归构建humidity节点,仍按照算法流程计算信息增益。 -
构建完成。到此决策树已经构造完成。由于所给数据集构造的决策树较简单,相对于其他数据集可能并非如此,在构造复杂的决策树时,对每个子集重复上述方法,直到满足停止条件。
4 例题二
-
数据集采用西瓜数据集,由于样本数据较简单,例题并没有考虑设置阈值。
-
初始化,构建根节点。如下图(4-1)所示,选择信息增益最大的纹理作为根节点,当纹理为模糊时,样本均为坏瓜,其他类型有好有坏。

-
递归构建D1。如下图(4-2)所示,当根蒂为蜷缩时,样本均为好瓜,当根蒂为硬挺时,样本均为坏瓜,其他类型有好有坏。

-
递归构建D3。如下图(4-3)所示,当色泽为青绿时,样本均为好瓜,但没有色泽为浅白的样本,其他类型有好有坏。

-
递归构建D4。如下图(4-4)所示,当触感为硬滑时,样本均为好瓜,反之为坏瓜。

-
递归构建D2。如下图(4-5)所示,当触感为软粘时,样本均为好瓜,反之为坏瓜。
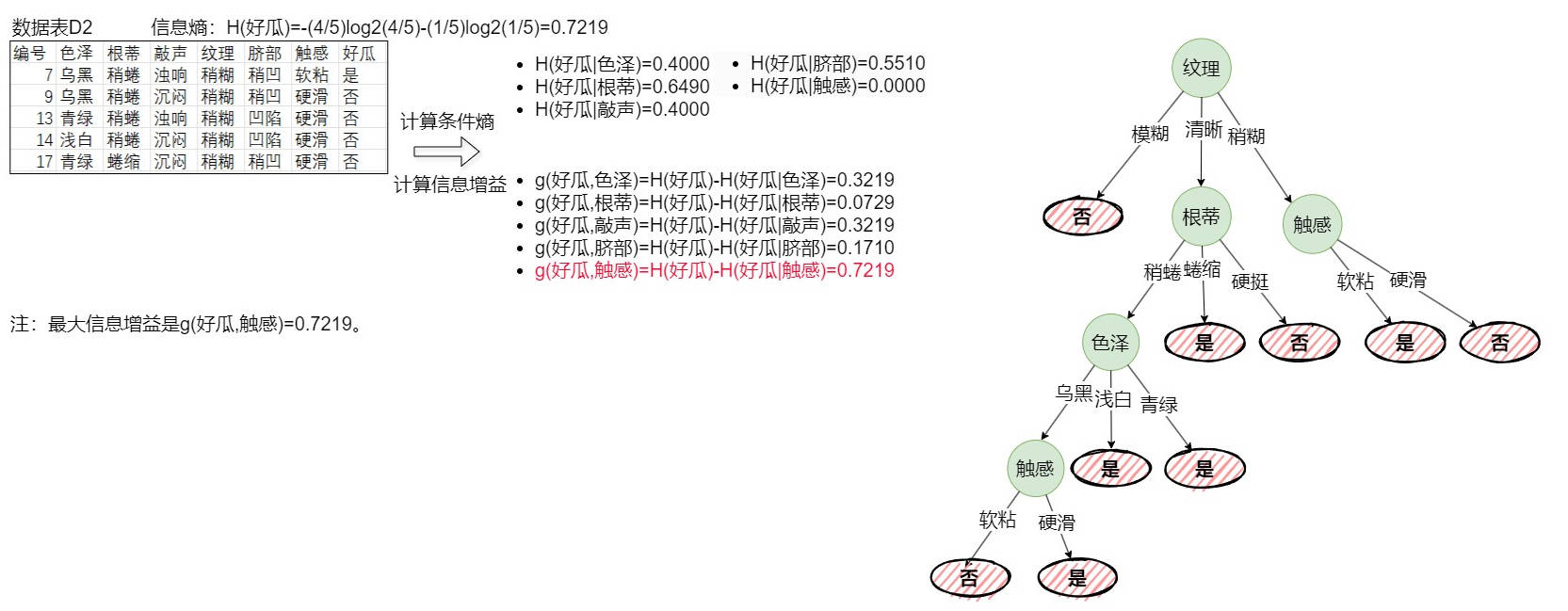
-
构建完成。所有节点都无法再进一步划分,此时所有节点构建完成。
5 算法优缺点
5.1 优点
- 算法原理简单,易于理解。
- 能够处理分类任务,并且分类速度快。
- 决策树模型的可解释性强,便于理解和分析。
5.2 缺点
- 只能处理离散值特征,对于连续值特征需要预先处理(如离散化)。
- 对缺失值敏感,需要进行额外的处理(如填充缺失值)。
- 倾向于选择取值较多的特征作为分裂特征,这可能导致模型不够稳定。
- 容易发生过拟合,特别是当决策树过于复杂时。
6 应用与展望
ID3算法广泛应用于分类问题中,如客户分类、疾病诊断、信用评估等。通过构建决策树模型,可以实现对未知样本的快速分类和预测。然而,在实际应用中,为了克服ID3算法的缺点,通常会采用其改进版本(如C4.5算法和CART算法)或结合其他机器学习算法进行集成学习。
7 结语
如有错误请指正,禁止商用。
1.本站内容仅供参考,不作为任何法律依据。用户在使用本站内容时,应自行判断其真实性、准确性和完整性,并承担相应风险。
2.本站部分内容来源于互联网,仅用于交流学习研究知识,若侵犯了您的合法权益,请及时邮件或站内私信与本站联系,我们将尽快予以处理。
3.本文采用知识共享 署名4.0国际许可协议 [BY-NC-SA] 进行授权
4.根据《计算机软件保护条例》第十七条规定“为了学习和研究软件内含的设计思想和原理,通过安装、显示、传输或者存储软件等方式使用软件的,可以不经软件著作权人许可,不向其支付报酬。”您需知晓本站所有内容资源均来源于网络,仅供用户交流学习与研究使用,版权归属原版权方所有,版权争议与本站无关,用户本人下载后不能用作商业或非法用途,需在24个小时之内从您的电脑中彻底删除上述内容,否则后果均由用户承担责任;如果您访问和下载此文件,表示您同意只将此文件用于参考、学习而非其他用途,否则一切后果请您自行承担,如果您喜欢该程序,请支持正版软件,购买注册,得到更好的正版服务。
5.本站是非经营性个人站点,所有软件信息均来自网络,所有资源仅供学习参考研究目的,并不贩卖软件,不存在任何商业目的及用途
![机器学习之——决策树信息增益比计算[程序+例题]-千百度社区](http://qbd.heng.ink/wp-content/uploads/2024/09/e69cbae599a8e5ada6e4b9a0e4b98b-e586b3e7ad96e6a091e4bfa1e681afe5a29ee79b8ae6af94e8aea1e7ae97e7a88be5ba8fe4be8be9a298_66e325f913aee.jpeg)








暂无评论内容