
本文分享自华为云社区《GaussDB(for MySQL)创新特性:灵活多维的二级分区表策略》,作者:GaussDB 数据库。
背景介绍
分区表及二级分区表的功能,可以让数据库更加有效地管理和查询大规模数据,传统商业数据库具备该能力。MySQL支持分区表,与传统商业数据库相比,MySQL对二级分区表功能的支持尚显不足,存在一定的功能差距。
为了弥补这一差距,GaussDB(for MySQL)发布了对二级分区表功能的支持。这一举措旨在让MySQL用户能够享受到与传统商业数据库类似的分区管理和查询优势,提高数据库的灵活性和性能。
GaussDB(for MySQL)致力于为用户提供更全面、更强大的数据库解决方案,满足其日益增长的数据管理需求。
分区表
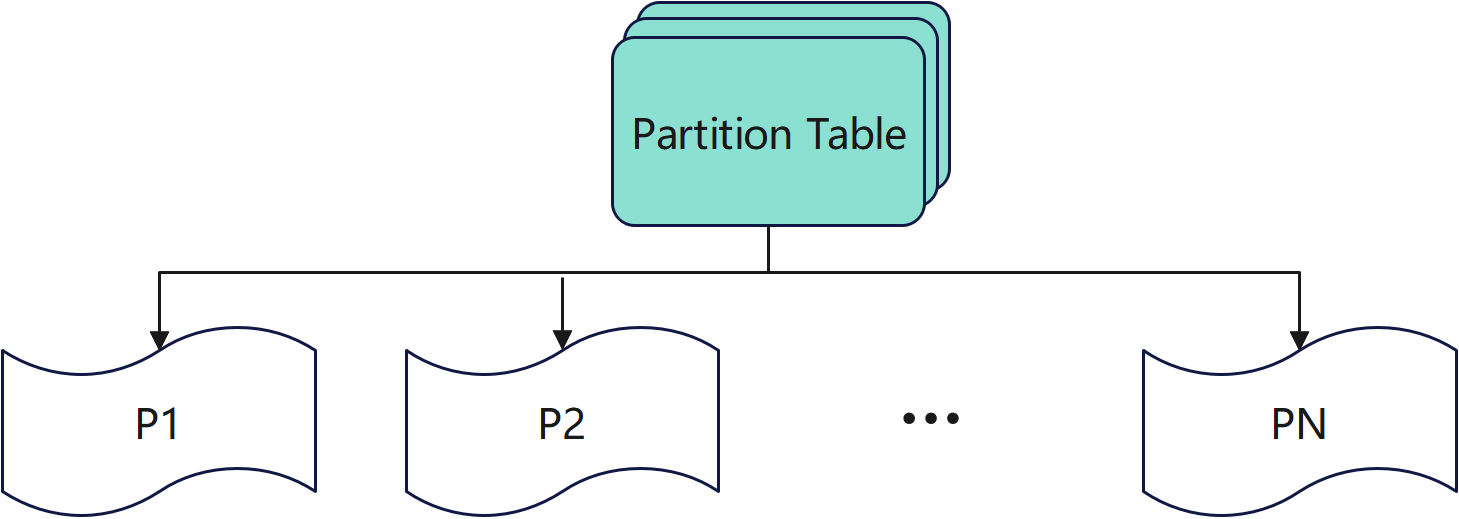
众所周知,分区表就是从逻辑上对一个表划分成多个分区,实现物理上的隔离或性能上的优化。GaussDB(for MySQL)继承了开源社区的分区表功能,能够为各个分区定义不同的引擎以及表空间等属性,方便用户管理。
随着表数据的膨胀,单纯的一个表很容易出现性能问题。如随着数据量的增加,查询数据量可能会随之变大,进而导致同一条查询语句性能也会随之下降。而分区表提供了解决大表问题的一个手段,将一张大表分成不同的分区,按照分区定义,合理的书写查询语句,可以使得数据量变化的情况下,查询性能的稳定。
另外一种情况就是,随着时间的推移,表数据中会出现冷数据,如何管理冷数据以及控制冷数据对查询性能的影响,分区表也是一个不错的手段。将冷数据归档到某个或者某几个分区,查询的时候只需查询热分区内的数据,可以避免对冷数据的影响。
一个分区表结构图如下所示:

二级分区表
二级分区,又称为子分区,是在一级分区的基础上进一步对数据进行细分的技术。在数据库表中,可以根据一个或多个字段的值将数据划分为不同的分区,这就是一级分区。而二级分区则是在一级分区的基础上,再根据其他字段的值对每个一级分区内的数据进行细分。
通过二级分区,可以将数据表划分为更小、更易于管理的片段,从而提高数据的存储效率和查询性能。具体来说,二级分区有以下优势:
- 灵活的数据管理:通过二级分区,可以根据业务需求和数据特点灵活地定义分区策略,实现数据的按需存储和查询。
- 提高查询效率:由于二级分区将数据划分为更小的片段,因此,在查询时可以只扫描相关的分区,减少不必要的数据扫描,从而提高查询速度。
- 便捷的数据备份和恢复:通过二级分区,只需备份或恢复特定的分区,而不是整个数据表,节省备份和恢复所需的时间和空间。
二级分区表更多的是从维度来考虑。当一级分区的数据量开始增加时,可以从另一个维度对其进行管理。例如,在一个销售情况表中,一级分区可以按地区进行划分,而二级分区可以按年份进行进一步划分。这样,当需要查询某地某年的情况时,只需访问二级分区内的数据,就可以获得很好查询的性能。
二级分区结构图如下:

分区表的优点
- 支持在分区级别而不是在整个表上进行数据加载、索引、创建和重建,以及备份和恢复等数据管理操作,可以大幅减少操作时间。
- 提高查询性能。通常可以通过访问分区的子集而不是整个表来获得查询的结果。对于某些查询,分区修剪技术可以提供数量级的性能提升,减少无效IO访问。
- 分区维护操作的分区独立性,允许用户对同一表或索引的一些分区执行维护操作,而同时保证无运维操作的分区运行并发和DML操作不受影响。查询以及DML和DDL支持并行执行。
- 如果将关键表和索引划分为分区以减少维护窗口,则可以提高关键应用的数据库可用性。
- 无需重写应用就可以利用分区能力。
- 更容易的数据生命周期管理能力。
特性介绍
1. 增强MySQL二级分区类型
GaussDB(for MySQL)对分区表类型进行了增强,组合分区中的二级分区支持更多类型(Range/List/Hash),满足客户不同场景、不同数据类型(如时间)。

2.支持List Default [Hash]
List Default [Hash] 分区是一种高级分区策略,用于优化数据管理和查询性能,特别是在处理长尾数据和多样化类别数据时。以下是对List Default [Hash] 分区的作用和应用场景的详细描述:
1)数据隔离
- 主要数据类别独立:通过列表分区(List Partitioning),可以将主要的数据类别(如特定类型的日志、订单状态、设备类型等)分离到独立的分区中。这样可以确保主要类别的数据在查询时不受其他类别数据的干扰,提高查询效率。
- 长尾数据管理:未明确分类的数据(通常是长尾数据)被放入默认分区(Default Partition),使得长尾数据与主要类别数据分离管理,减少了对主要数据类别的影响。
2)数据均匀分布
- 哈希分区(Hash Partitioning):将默认分区中的数据按哈希算法均匀分布到多个子分区中。这种方式可以避免数据在单一分区中过于集中,防止单一分区成为性能瓶颈,提升查询和管理效率。
3)查询优化
- 减少扫描范围:在查询时,只需扫描相关的分区,而不需要扫描整个表的数据,从而显著减少I/O操作,提高查询性能。
- 平衡负载:通过哈希分区将长尾数据均匀分布在多个分区中,避免某个分区的数据量过大,提升数据库的并发处理能力和响应速度。
4)灵活数据管理
- 独立维护:不同分区的数据可以独立进行维护、备份和归档,提升数据管理的灵活性和效率。
- 动态扩展:当数据量增加时,可以动态增加分区,通过调整哈希分区的数量来平衡负载和优化性能。
3. 支持RANGE INTERVAL 分区
RANGE INTERVAL分区是一种基于范围的分区策略,其中数据根据指定的范围进行分区,并且可以自动创建新的分区以处理未来的数据。这种方法特别适用于时间序列数据等连续增长的数据集。下面是RANGE INTERVAL 分区的优势:
1)自动分区:不需要手动定义每个分区,当新数据超出现有分区范围时,数据库会自动创建新的分区。
2)减少DBA工作量:DBA 不再需要频繁地监控数据增长并手动创建分区,系统会根据数据量动态调整分区。
3)查询优化:查询时只需扫描相关的分区,而不是整个表,从而提高查询效率。
4)易于管理:简化了数据管理,尤其是对于不断增长的数据集。
分区表的应用场景
分区表可以更好的应用到哪些用户场景?
日志数据分析
应用场景:
- 服务器日志管理:在大型网站或应用中,服务器每天会生成大量的访问日志、错误日志等,使用分区表可以按天、按类型(访问日志、错误日志)进行分区,也可以先按日期进行一级分区,然后按日志类型(如访问日志和错误日志)进行二级分区。
- 安全日志分析:在安全系统中,需要对大量的安全事件日志进行分析,通过分区表按事件时间、事件类型(入侵检测、登录失败等)进行分区,可以快速定位并分析特定时间段或类型的安全事件,也可以先按事件时间进行一级分区,然后按事件类型(如入侵检测、登录失败)进行二级分区。
- 应用性能监控:在应用性能监控系统中,每天会产生大量的性能数据日志,通过分区表按应用模块、时间进行分区,可以快速分析某一模块在特定时间段的性能表现。也可以按照应用模块进行一级分区,然后按照时间段进行二级分区。
优点:
- 快速查询:针对特定时间段或类型的日志进行查询时,只需扫描相关分区,避免全表扫描,极大提高查询速度。
- 存储管理:不同时间段的日志数据可以按需保留或删除,便于数据归档和管理。
电商交易数据分析
应用场景:
- 订单管理:电商平台每天会产生大量的订单数据,通过分区表按订单号、交易时间、用户ID等进行分区,可以快速查询某个用户的所有订单或特定时间段的订单。也可以先按交易日期进行一级分区,再按用户ID或订单状态(如待支付、已支付、已发货)进行二级分区。
- 用户行为分析:分析用户的购物行为,例如用户在某一时间段内的购买频次、偏好等,通过分区表按用户ID、行为时间进行分区,有助于精准营销。也可以先按行为时间进行一级分区,然后按用户ID或行为类型(如浏览、下单、支付)进行二级分区。
- 库存管理:电商平台需要实时监控库存,通过分区表按商品ID、时间进行分区,可以快速查询某个商品在不同时期的库存变动情况。也可以先按行为时间进行一级分区,然后按商品ID进行二级分区。
优点:
- 高效查询:针对某用户或某时间段的交易数据查询时,减少不必要的数据扫描,提高查询效率。
- 数据管理:按时间分区可以方便地进行历史数据归档和删除,优化存储空间。
物联网数据分析
应用场景:
- 设备状态监控:物联网系统中需要实时监控设备状态,通过分区表按设备ID、时间戳进行分区,可以快速获取设备的实时数据或历史数据。也可以先按设备ID进行一级分区,再按数据时间戳进行二级分区。
- 环境数据监测:在环境监测系统中,需要对不同地点的环境数据进行监测,通过分区表按地点ID、时间戳进行分区,可以快速查询某一地点的环境变化情况。也可以先按监测地点进行一级分区,然后按数据时间戳进行二级分区。
- 智能家居:智能家居设备生成大量的数据,如温度、湿度、用电量等,通过分区表按设备ID、时间进行分区,可以有效管理和分析家庭设备的数据。也可以先按行为时间进行一级分区,然后按设备ID进行二级分区。
优点:
- 实时性:可以快速查询某个设备的实时数据,满足实时监控需求。
- 历史分析:方便查询和分析设备的历史数据,识别长期趋势和异常情况。
金融行业数据分析
应用场景:
- 账户管理:金融机构需要管理大量的账户信息和交易记录,通过分区表按账户类型(个人账户、企业账户)、交易时间进行分区,可以快速查询某个账户的交易记录。也可以先按账户类型(如个人账户、企业账户)进行一级分区,再按交易时间进行二级分区。
- 风险控制:在风险控制中,需要分析大量的交易数据,识别异常交易,通过分区表按交易时间、交易类型进行分区,可以高效定位并分析可疑交易。也可以先按交易时间进行一级分区,然后按交易类型(如存款、取款、转账)进行二级分区。
- 投资分析:金融机构需要对投资数据进行分析,通过分区表按投资产品类型、时间进行分区,可以快速查询某类产品在不同时间段的表现,辅助投资决策。也可以先按交易时间进行一级分区,然后按投资产品类型类型(如股票、债券、基金等)进行二级分区。
优点:
- 高效数据分析:针对特定账户或时间段的金融数据查询时,减少数据扫描,提高查询速度。
- 精准风险管理:方便对特定类型或时间段的交易进行细致分析,及时发现并应对风险。
综上列举了部分适合分区表策略的一些应用场景,可以看出分区表在各种应用场景中,都能显著提高数据查询和分析的效率,便于数据管理和维护。通过合理设计分区策略(一级以及二级分区),针对性地进行数据分区,可以有效优化数据库性能,满足不同场景下的业务需求。
总结
分区表和二级分区表技术为大型数据库系统提供了一种高效的数据存储和查询方案。通过灵活定义分区策略和数据划分方式,可以实现数据的按需存储和查询,提高数据处理效率和分析能力。随着数据量的不断增长和业务需求的不断变化,分区表和二级分区表技术将在更多领域得到应用和发展,为数据管理提供更加灵活和高效的解决方案。
1.本站内容仅供参考,不作为任何法律依据。用户在使用本站内容时,应自行判断其真实性、准确性和完整性,并承担相应风险。
2.本站部分内容来源于互联网,仅用于交流学习研究知识,若侵犯了您的合法权益,请及时邮件或站内私信与本站联系,我们将尽快予以处理。
3.本文采用知识共享 署名4.0国际许可协议 [BY-NC-SA] 进行授权
4.根据《计算机软件保护条例》第十七条规定“为了学习和研究软件内含的设计思想和原理,通过安装、显示、传输或者存储软件等方式使用软件的,可以不经软件著作权人许可,不向其支付报酬。”您需知晓本站所有内容资源均来源于网络,仅供用户交流学习与研究使用,版权归属原版权方所有,版权争议与本站无关,用户本人下载后不能用作商业或非法用途,需在24个小时之内从您的电脑中彻底删除上述内容,否则后果均由用户承担责任;如果您访问和下载此文件,表示您同意只将此文件用于参考、学习而非其他用途,否则一切后果请您自行承担,如果您喜欢该程序,请支持正版软件,购买注册,得到更好的正版服务。
5.本站是非经营性个人站点,所有软件信息均来自网络,所有资源仅供学习参考研究目的,并不贩卖软件,不存在任何商业目的及用途














暂无评论内容