
简介
因为身处在应对ToB需求的SAAS行业,复杂的需求在代码上造成的混乱始终是我们的一大困扰,所以我们在一些项目中尝采用整洁架构的分层模式对部分代码做了一些改善和实践。
在这篇文章中我来分享一下我在分层架构上的思考,一些实践方法。
为什么要分层?
我们都知道ToB行业的一大特点就是需求非常复杂,我们面对的客户都是大型企业,企业的流程和需求都各不相同。
可以想象一下,当你在家里用两个路由器去组建一个网络的时候,还是比较简单的事情。但当你需要帮助一个机房几百个交换机组建网络的时候,这个事情就会变得复杂起来。更大规模的组网需求导致了这个这个组网工作的复杂度陡增。
再举一个例子,把你丢在一个只有四栋楼的陌生小区里不给你任何的工具,让你走出这个小区,我相信你能很快走出这个小区;但是把你丢在一个陌生城市里不给你任何的工具,让你去一个指定的地点,你是很容易迷路的。更大规模的路线需要你去了解,如果没有地图,你很难凭借自己的判断来了解这个城市的路线。
由此可见复杂性和规模有很大的关系,再回到我们系统面临的问题上,随着系统承载的需求规模的增加,需求之间交叉的影响会越来越多,对系统的全面理解会越来越困难。
在《A Philosophy of Software Design》这本书中总结了三种复杂症状:
- 变更放大(Change amplification): 看似简单的变更需要在许多不同地方进行代码修改。
- 认知负荷(Cognitive load): 开发人员需要许多知识才能完成一项任务。
- 未知的未知(Unknown unknowns): 开发人员在参与开发的工作中,不知道自己不知道什么。
分层架构很大程度上就是在试图解决这几种复杂症状,通过分层架构,我们将系统不断拆解,分离形成自治的稳定空间,去降低系统的认知负担和理解成本,简化和明确系统变更造成的影响范围。
分层架构的探索过程
巨人的肩膀
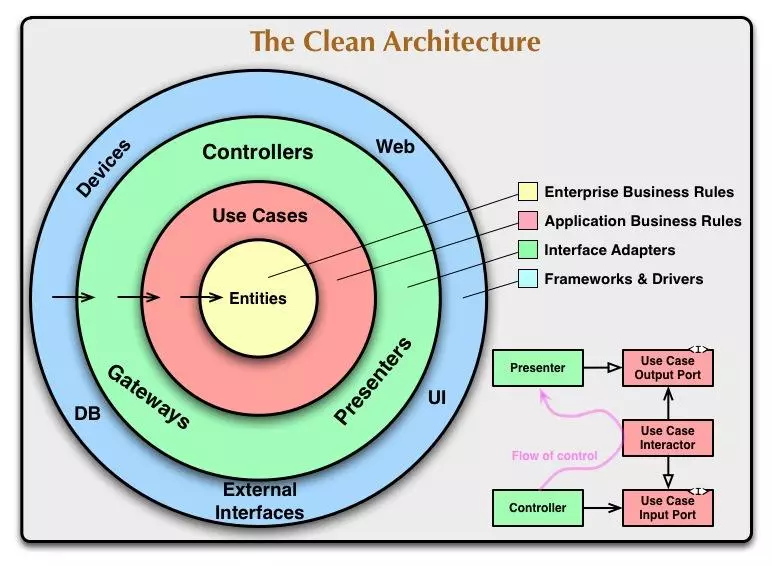
说到分层架构,除了经典的三层架构之外,最出名的就是Uncle Bob的《架构整洁之道》中提到的整洁架构了,他的关键结构表示如下:
除此之外,在DDD的六边形架构中,也有差不多的一个分层架构:
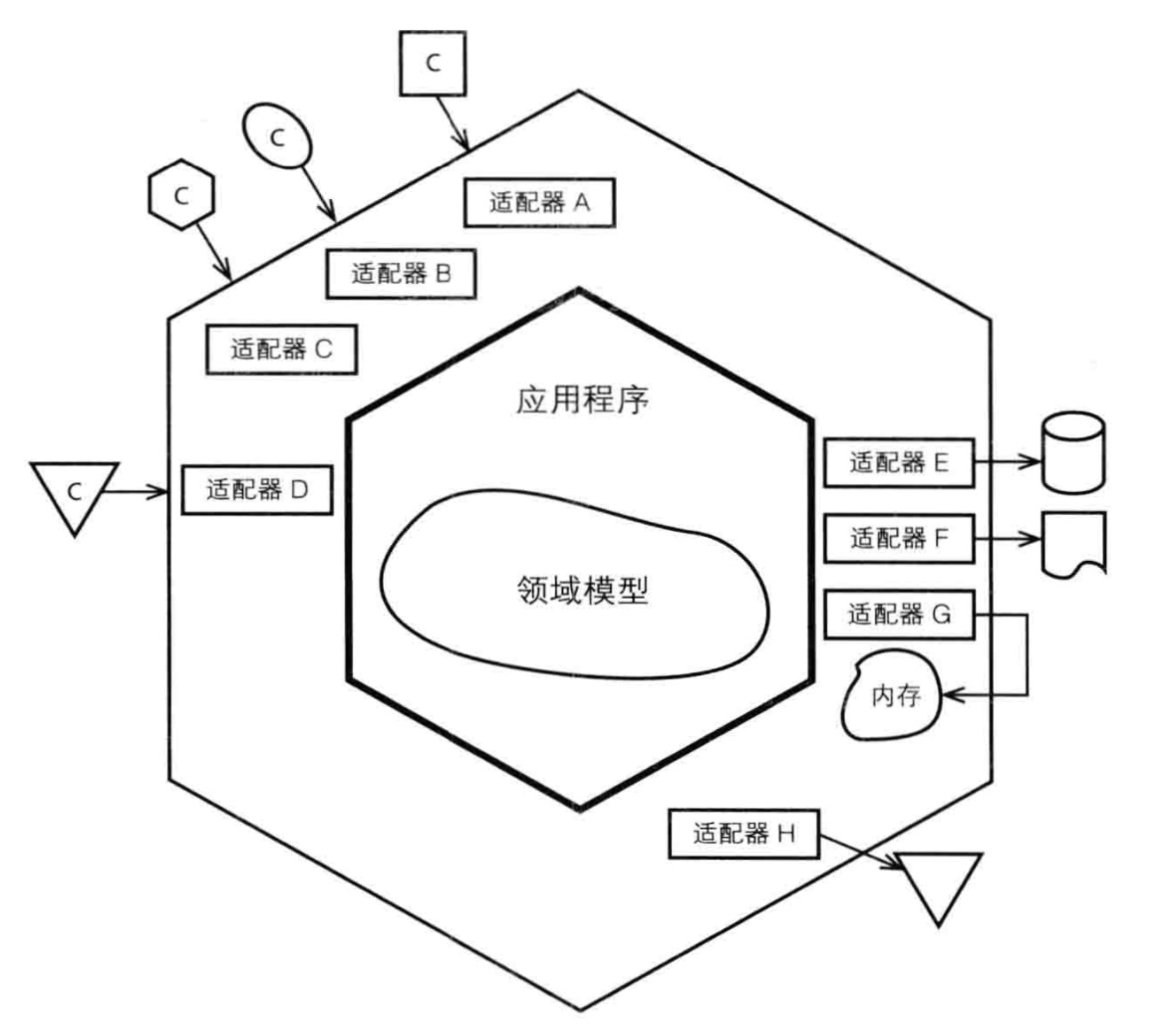
六边形架构给出了更加具体的层次,他将代码的层次分为了四层架构的:
- 用户展示层
- 应用服务层
- 领域层
- 基础设施层
几个层次之间的依赖关系如下:
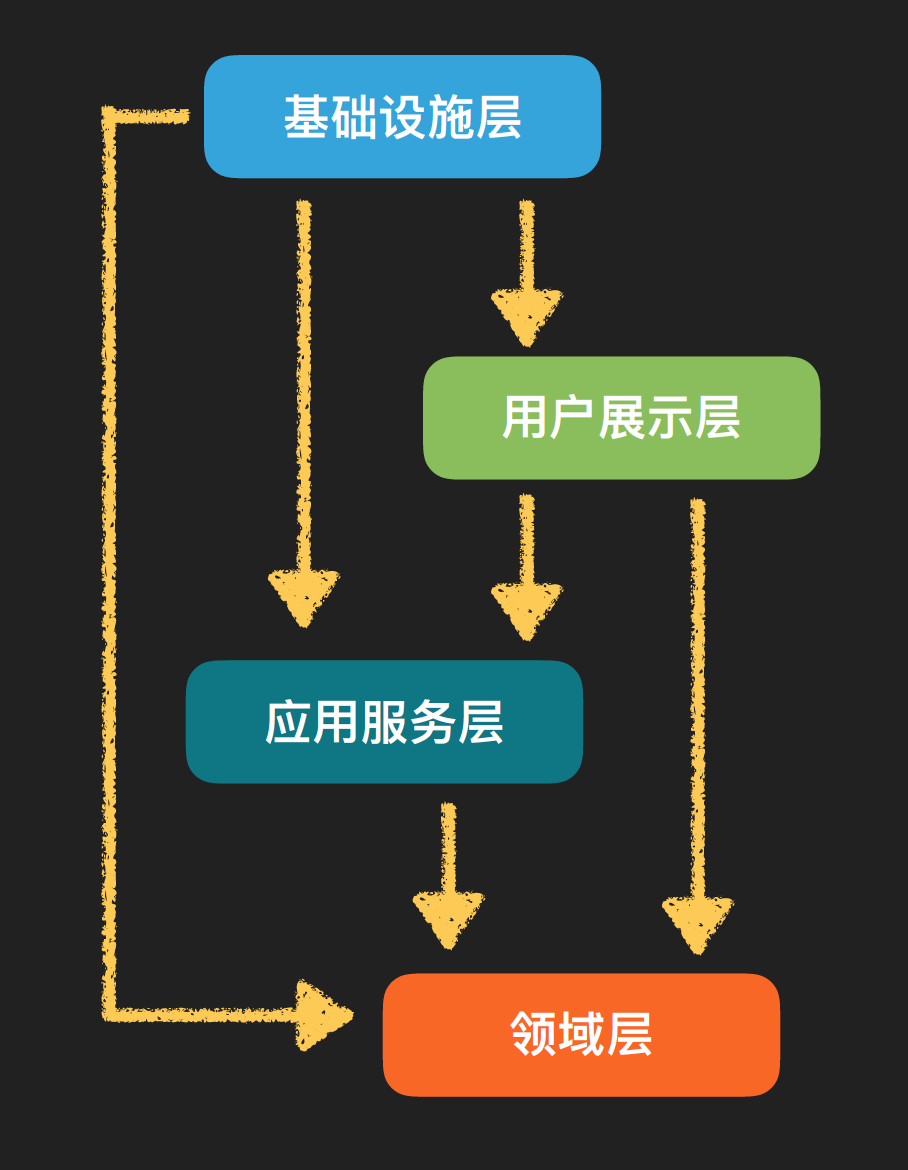
其实以上提到的两种模式核心的想法都是一样的,以自己要承载的目标业务对象为最底层,高层代码允许依赖底层,但是底层代码不要依赖高层,这也是对依赖倒置原则很好的实践。
项目分包结构思考过程
我们通过学习整洁架构和六边形架构的内容,将他们的思想映射到系统中,我们形成了这样的分包演进路线,按照四层架构的分层,我们可以先将系统分成以下几个package:
.
├── view // 视图
├── usecase // 用例
├── domain // 领域层
└── infrastructure // 基础设施
在现实项目中会遇到几个问题:
- 系统会存在一些配置信息,存放项目所需要的配置类
- 像目前前后端分离的情况下,前端的页面作为用户展示层并不会放入后端的项目, 所以view层需要被移除掉。
- 用例usecase往往与具体的业务有关,我们将其与domain的对象聚合在一个package下,所以将usecase层移除
这样思考之后,我们形成了这样的一个目录结构:
.
├── config // 配置类
├── domain // 领域层
└── infrastructure // 基础设施
以上的每个package(用例,领域层,基础设施)都分开分析一下,先看基础设施,实际上,基础设施是分为两个维度的的:
- 对外暴露的服务接口,可以命名为gateway,表示对外的接入层
- 对外部中间件和数据库的依赖框架,也是我们最习惯认为的基础设施
将这个package结构继续改进之后,形成这样的结构:
.
├── config // 配置类
├── domain // 领域层
├── gateway // 视图
└── infrastructure // 基础设施
在项目中还会存在非常基础和通用的代码,这个部分的基础设施实际上是横跨整个项目,有点像是当前这个项目中java.lang包,我们将其命名为tool。
.
├── config // 配置类
├── domain // 领域层
├── gateway // 视图
├── infrastructure // 基础设施
└── tool // 基础工具包
截止到以上的部分,就是第一级比较宏观的分层了。但是一套业务系统之中,其核心还是业务,如何在domain这个包下面要划分package,则真的要完全基于业务来进行划分了,从技术层面对这些层次(用例,基础设施等等)定义,还能有一些通用的说法,但是业务千变万化,是很难有通用的划分层次的,所以对业务进行划分也是最难的。
我们的业务中会分为几种不同的业务:
- 核心业务: 我们系统核心卖点,具有清晰的业务目标的业务
- 支撑业务: 支持着核心业务多个模块完成运转的业务,比如发送短信消息,发送开发者回调,文件存储等等。
所以domain下面我们可以分为这样两个包:
.
├── corebiz // 核心业务
└── support // 支撑业务
对于任何一个核心业务或支撑业务的单一的小范围业务而言,他们最好是都能独立自治,形成一个迷你系统,根据《架构整洁之道》中的模型,每个业务package可以分为这样几个层次:
.
├── application // 应用服务
│ └── param // 与用例相关的入参和出参
├── acl // 防腐层
├── model // 领域对象
├── repo // 仓储层
└── service // 领域服务
以下是对上面分包每一种package结构的解释:
- application包中, 存放业务的主流程
- 前面提到的usecase,表达业务的动作
- 能讲明白业务的流程,表达业务的含义,不要出现复杂的数据组装逻辑和和复杂的判断逻辑
- 具体的业务判断逻辑在domainService或者model中完成
- 数据组装逻辑应该尽量在基础设施层完成
- acl是对外部系统的调用,使用Java interface表示
- 当业务使用到外部系统的时候,使用ACL屏蔽外部对接的实现,让业务只关心做什么,而不是怎么做。
- 命名应该采用具有业务含义的命名,不要出现:RedisClient、CacheClient,MySQLClient等等,应该出现: IMessageClient, IUserClient等等
- model是对业务对象的呈现
- 每个业务应该尽量新建自己的业务model,复用对象应该谨慎,避免出现过大的类,大类容易出现信息过载,当自己使用get方法找属性要停顿思考一下的时候就意味着类太大了。
- model的类可以有一些自己的行为方法(method)
- 业务对象其实是有分类的:
- entity:具有完整生命周期的对象,就是完整的具有业务含义的对象,比如:Receiver、Label、Document
- value object:值对象,本身只是为了承载一些数据,离开entity没有意义,例如Label的Position对象
- aggregate:表示聚合,当多个entity需要协作会内聚到一个聚合中,聚合也是核心的业务操作对象,比如:AutoSignContract
- repo表达的是model的数据源,使用Java interface表示
- 应该仅考虑给聚合model提供repo
- 数据的组装在实现中完成
- domain service:
- domain service相当于业务对象(model)的延伸
- domain service应该只处理与自己对应model相关的业务,比如:ReceiverDomainService只处理Receiver相关方法,不要出现以处理Document对象为主的方法。
- 每个方法应该只完成一个动作(粒度要小),靠application service编排domain service的方法
经过以上的思考和定义之后,我们形成了这样的一个分层架构:
.
├── config // 配置类
├── domain // 领域层
│ ├── corebiz // 核心业务
│ │ ├── business1
│ │ │ ├── application // 应用服务,usecase
│ │ │ │ └── param // 与用例相关的入参和出参
│ │ │ ├── acl // 防腐层
│ │ │ ├── model // 领域对象
│ │ │ ├── repo // 仓储层
│ │ │ └── service // 领域服务
│ │ └── business2
│ └── support // 支撑业务
│ │ ├── business3
│ │ │ ├── application // 应用服务,usecase
│ │ │ │ └── param // 与用例相关的入参和出参
│ │ │ ├── acl // 防腐层
│ │ │ ├── model // 领域对象
│ │ │ ├── repo // 仓储层
│ │ │ └── service // 领域服务
│ │ └── business4
├── gateway // 视图
├── infrastructure // 基础设施
└── tool // 基础工具包
有了业务的分层之后,两个基础设施层(gateway和infrastructure)要开始适配我们的业务分层。
先看gateway,它要作为对外暴露的协议接入层,所以不同的协议上会有一些集中处理,所以我们给出了这样的分层:
.
└── gateway // 协议接入层
├── dubbo // Dubbo协议层
├── http // HTTP协议接入层
├── mq // MQ协议接入层
└── schedule // 定时任务接入层
另外一遍infrastructure会包含很多中间件的本身的代码,还有一部分是中间件的代码和业务代码交互的部分,所以应该形成这样的结构去承载这两种功能:
.
└── infrastructure // 基础设施层
├── impl // 业务代码和基础设施的适配层
│ ├── corebiz
│ │ ├── business1 // 与domain层的package分类要适配
│ │ │ ├── acl // 防腐层实现
│ │ │ └── repo // 仓储层实现
│ │ └── business2
│ └── support
│ ├── business3 // 与domain层的package分类要适配
│ │ ├── acl // 防腐层实现
│ │ └── repo // 仓储层实现
│ └── business4
├── mysql // mysql的客户端实现,存放比如数据库的映射代码,XXXDAO等,方便impl统一调用
├── redis // redis的客户端实现,存放一些和redis交互代码,方便impl统一调用
├── kafka // kafka的客户端实现,存放一些和kafka交互代码,方便impl统一调用
└── thirdparty // 与第三方系统交互的适配代码,方便impl统一调用
还剩下一个部分没有进行分包,那就是tool,之前提到说这个包下主要是当做这个项目的java.lang包用的,也就是一些可以在项目中比较通用的代码,这个包下的分类就比较看自己项目的需求了, 对于我们而言,比较通用的代码有这些:
- symbol
- document
.
└── tool // 工具代码
├── livingdocument // 我们的业务文档注解聚集地
├── symbol // 一些标记代码
└── utils // 一些常用的Utils,比如StringUtils,PDFUtils等等
但是一定要注意tool这个包下对代码的规模控制,否则也会造成过多的信息,导致出现大量无用的Utils。
至此,我们形成了这样的一个分层架构:
.
├── config // 配置类
├── domain // 领域层
│ ├── corebiz // 核心业务
│ │ ├── business1
│ │ │ ├── application // 应用服务,usecase
│ │ │ │ └── param // 与用例相关的入参和出参
│ │ │ ├── acl // 防腐层
│ │ │ ├── model // 领域对象
│ │ │ ├── repo // 仓储层
│ │ │ └── service // 领域服务
│ │ └── business2
│ └── support // 支撑业务
│ │ ├── business3
│ │ │ ├── application // 应用服务,usecase
│ │ │ │ └── param // 与用例相关的入参和出参
│ │ │ ├── acl // 防腐层
│ │ │ ├── model // 领域对象
│ │ │ ├── repo // 仓储层
│ │ │ └── service // 领域服务
│ │ └── business4
├── gateway // 协议接入层
│ ├── dubbo // Dubbo协议层
│ ├── http // HTTP协议接入层
│ ├── mq // MQ协议接入层
│ └── schedule // 定时任务接入层
├── infrastructure // 基础设施
│ ├── impl // 业务代码和基础设施的适配层
│ │ ├── corebiz
│ │ │ ├── business1 // 与domain层的package分类要适配
│ │ │ │ ├── acl // 防腐层实现
│ │ │ │ └── repo // 仓储层实现
│ │ │ └── business2
│ │ └── support
│ │ ├── business3 // 与domain层的package分类要适配
│ │ │ ├── acl // 防腐层实现
│ │ │ └── repo // 仓储层实现
│ │ └── business4
│ ├── mysql // mysql的客户端实现,存放比如数据库的映射代码,XXXDAO等,方便impl统一调用
│ ├── redis // redis的客户端实现,存放一些和redis交互代码,方便impl统一调用
│ ├── kafka // kafka的客户端实现,存放一些和kafka交互代码,方便impl统一调用
│ └── thirdparty // 与第三方系统交互的适配代码,方便impl统一调用
└── tool // 基础工具包
├── livingdocument // 我们的业务文档注解聚集地
├── symbol // 一些标记代码
└── utils // 一些常用的Utils,比如StringUtils,PDFUtils等等
这里通过一个图例更加直观地说明这个层次结构:
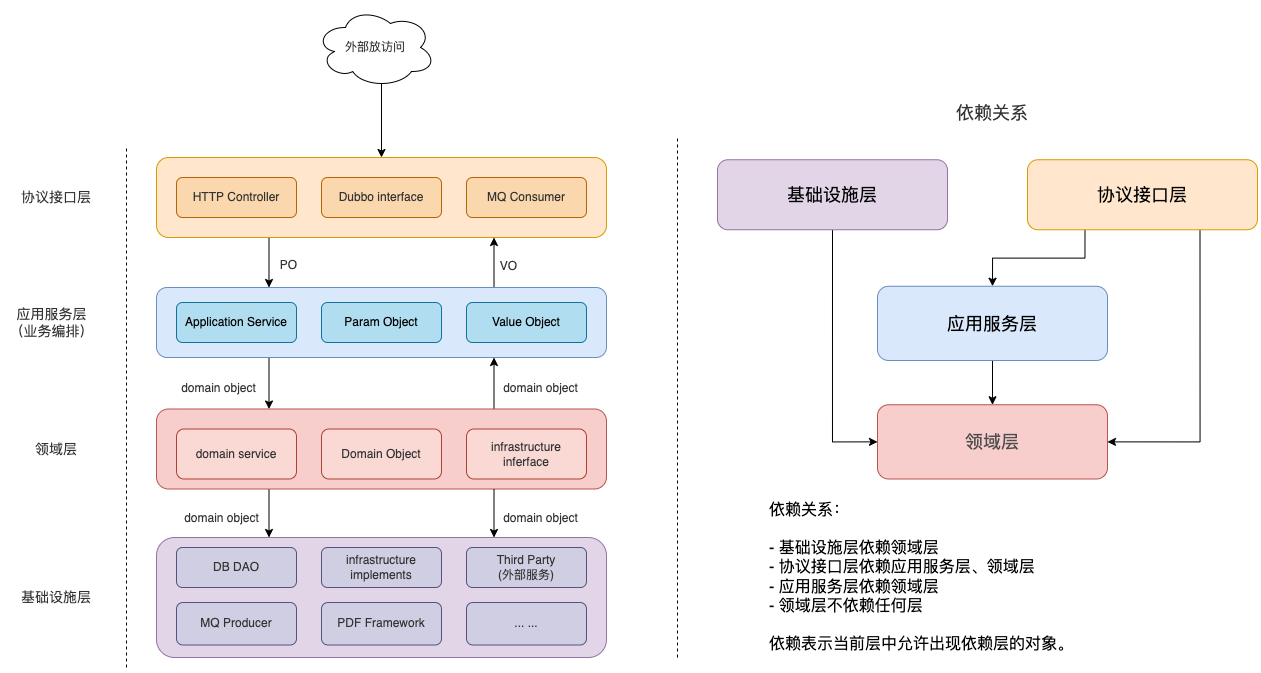
分层架构的实践
如何在项目中加入分层架构
在探索得到这样的一个分层架构之后,首要面临的问题就是如何将这样的架构应用到系统中,也不会对系统造成很大的影响。在敏捷开发中,很重要的一个实践就是要做精益交付,就是一次性不要尝试做大型交付,比如将系统推到重来,或者一次交付一个需要几周才能完成的工作,要想办法尽快让其有反馈。
在不影响原来的代码的情况下,我们决定在项目中添加了新的一个package,使得形成这样的一个结构:
.
├── extant-package // 现有的代码package
└── new-package // 分层架构的package
这样我们在找定一个业务中之后,可以在不影响原来项目的情况下立马开始实践,即使出问题了,在发布分支上删除掉整个package也没有问题。(可以Google查询Martin Fowler的“绞杀者模式”)
新旧需求如何使用分层架构
新需求往往包含着一些完整的业务逻辑,所以可以比较方便在分层架构下构建代码,在这种分层架构下新编写业务逻辑,然后暴露协议给外部或者老代码使用。
对于一些老的需求,我们也是采用了演进式的方式来进行适配,我们会把老需求修改的部分通过分层架构进行编写,然后暴露一个interface给老代码去使用。
但不论是新需求还是老的需求改造,其中非常重要的两件事情:
- 每一个business package下要能够独立自治,形成高度内聚的逻辑,这样就能一定程度上减缓Unkonw unkonws的困扰。
- 每一个business package下的规模要足够的小,只有足够的小,才能让后面来维护的其他人认知负担小,让这个模块可以做到快速交付。
对于代码层面具体的编写是一个比较大的内容,我们会单独去写一篇文章来进行分享。
分层架构是如何帮助单元测试的
单元测试一直是我们希望去强调的一个质量保证手段,但是很长一段时间单元测试的执行效果是不理想的,但分层架构一定程度上帮助到了单元测试的推进。
原来单元测试对于大部分开发同事来说是最痛苦的就是运行它,因为一段充满了依赖和坏味道的代码其实是不好运行的,也非常慢,这也阻碍了我们进行测试。单元测试本意是为了测试我们那一小块业务逻辑,我们并不应该将无关的代码启动起来,通过分层架构我们可以将基础设施和业务代码分开。
前面我们提到了一个business的结构如下:
.
├── application // 应用服务
│ └── param // 与用例相关的入参和出参
├── acl // 防腐层,只有interface
├── model // 领域对象
├── repo // 仓储层,只有interface
└── service // 领域服务
我们只去测试business代码,从application为入口,进行测试。由于ACL和Repo都是interface,我们很容易就能mock这些interface,给这些interface一些我们预期的输入和返回值,然后验证我们在application中的编排和业务逻辑是否是正确的,这里去构建单元测试的时候,是不需要借助任何运行时候的框架的(比如spring,Dubbo等等),仅仅是我们在验证业务逻辑,快速获得我们编写的业务逻辑是否符合我们的预期。
这里尤其要注意使用spring的项目,做IOC注入的时候应该使用构造器注入或者是setter注入,这样才能方便单元测试。
如何管理日益新增的需求
随着需求日益增加,package会陷入另外一种混乱。给大家感受一下:
.
├── corebiz
│ ├── business1
│ ├── business2
│ ├── business3
│ ├── business4
│ ├── business5
│ ├── business6
│ ├── business7
│ ├── business8
...
│ └── business100
└── support
├── business1
├── business2
├── business3
├── business4
├── business5
├── business6
├── business7
├── business8
...
└── business50
由于过多的package,还是会陷入另外一种由于规模造成的认知负担。如果我们可以有一个需求目录,想象一下如果用脑图的形式让你组织自己负责的产品现在的需求目录你会怎么做?经过精心地整理,是否可以整理成这样:
.
├── corebiz
│ ├── business1
│ │ ├── business1.1
│ │ ├── business1.2
│ │ └── business1.3
│ ├── business2
│ │ ├── business2.1
│ │ ├── business2.2
│ │ └── business2.3
│ ├── business3
│ │ ├── business3.1
│ │ │ ├── business3.1.1
│ │ │ ├── business3.1.2
│ │ └── business3.2
│ └── business4
└── support
├── business1
│ ├── business1.1
│ ├── business1.2
│ └── business1.3
├── business2
│ ├── business2.1
│ ├── business2.2
│ └── business2.3
└── business3
可以让这些package本身就组织地与文档一样,在需求演进的过程中设定一个规则,若模块超过x个,就进行拆分。最终的目的一定是:
- 让这个结构本身成为文档,让package的名称具有业务含义
- 让这个结构认知负担低,方便其他人查找。
由此还可以可见,当这个package下的目录达到一定的规模之后,我们就应该思考,这个系统是否应该进行拆分了。
总结
以上就是我们对于分层架构的探索实践的分享,《架构整洁之道》中有这么一句话来形容软件架构的目标:
软件架构的最终目标是:用最小的人力成本来满足构建和维护系统的需求。
通过分层架构的实践,产出的代码一定程度上降低了大家理解系统的认知负担,改善了修改系统的成本,算是达到了我们使用分层架构的目的。
1.本站内容仅供参考,不作为任何法律依据。用户在使用本站内容时,应自行判断其真实性、准确性和完整性,并承担相应风险。
2.本站部分内容来源于互联网,仅用于交流学习研究知识,若侵犯了您的合法权益,请及时邮件或站内私信与本站联系,我们将尽快予以处理。
3.本文采用知识共享 署名4.0国际许可协议 [BY-NC-SA] 进行授权
4.根据《计算机软件保护条例》第十七条规定“为了学习和研究软件内含的设计思想和原理,通过安装、显示、传输或者存储软件等方式使用软件的,可以不经软件著作权人许可,不向其支付报酬。”您需知晓本站所有内容资源均来源于网络,仅供用户交流学习与研究使用,版权归属原版权方所有,版权争议与本站无关,用户本人下载后不能用作商业或非法用途,需在24个小时之内从您的电脑中彻底删除上述内容,否则后果均由用户承担责任;如果您访问和下载此文件,表示您同意只将此文件用于参考、学习而非其他用途,否则一切后果请您自行承担,如果您喜欢该程序,请支持正版软件,购买注册,得到更好的正版服务。
5.本站是非经营性个人站点,所有软件信息均来自网络,所有资源仅供学习参考研究目的,并不贩卖软件,不存在任何商业目的及用途








暂无评论内容