

概述
项目组件
一个完整的transformer模型主要包含三部分:Config、Tokenizer、Model。
Config
用于配置模型的名称、最终输出的样式、隐藏层宽度和深度、激活函数的类别等。
示例:
{
"architectures": [
"BertForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"gradient_checkpointing": false,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 0,
"position_embedding_type": "absolute",
"transformers_version": "4.6.0.dev0",
"type_vocab_size": 2,
"use_cache": true,
"vocab_size": 30522
}
Tokenizer
将纯文本转换为编码的过程(注意:该过程并不会生成词向量)。由于模型(Model)并不能识别(或很好的识别)文本数据,因此对于输入的文本需要做一层编码。在这个过程中,首先会将输入文本分词而后添加某些特殊标记([MASK]标记、[SEP]、[CLS]标记),比如断句等,最后就是转换为数字类型的ID(也可以理解为是字典索引)。
示例:
pt_batch = tokenizer(
["We are very happy to show you the 🤗 Transformers library.",
"We hope you don't hate it."],
padding=True,
truncation=True,
max_length=5,
return_tensors="pt"
)
## 其中,当使用list作为batch进行输入时,使用到的参数注解如下:
## padding:填充,是否将所有句子pad到同一个长度。
## truncation:截断,当遇到超过max_length的句子时是否直接截断到max_length。
## return_tensors:张量返回值,"pt"表示返回pytorch类型的tensor,"tf"表示返回TensorFlow类型的tensor,"np"表示Numpy数组。
Model
AI模型(指代基于各种算法模型,比如预训练模型、深度学习算法、强化学习算法等的实现)的抽象概念。
除了初始的Bert、GPT等基本模型,针对下游任务,还定义了诸如BertForQuestionAnswering等下游任务模型。
Transformer使用
pipeline的使用
transformer库中最基本的对象是pipeline()函数。它将模型与其必要的预处理和后处理步骤连接起来,使我们能够直接输入任何文本并获得可理解的答案:
from transformers import pipeline
classifier = pipeline("sentiment-analysis")
classifier("I've been waiting for a HuggingFace course my whole life.")
[{'label': 'POSITIVE', 'score': 0.9598047137260437}]
默认情况下,该pipeline函数选择一个特定的预训练模型,该模型已经过英语情感分析的微调。当创建classifier对象时,将下载并缓存模型。如果重新运行该命令,则将使用缓存的模型,并且不需要再次下载模型。
调用pipeline函数指定预训练模型,有三个主要步骤:
- 输入的文本被预处理成模型(Model)可以理解的格式的数据(就是上述中Tokenizer组件的处理过程)。
- 预处理后的数据作为输入参数传递给模型(Model)。
- 模型的预测结果(输出内容)是经过后处理的,可供理解。
目前可用的pipelines如下:
- feature-extraction(特征提取)
- fill-mask
- ner(命名实体识别)
- question-answering(自动问答)
- sentiment-analysis(情感分析)
- summarization(摘要)
- text-generation(文本生成)
- translation(翻译)
- zero-shot-classification(文本分类)
完整说明可参考:pipelines示例说明
pipeline的原理
如上所述,pipeline将三个步骤组合在一起:预处理、通过模型传递输入以及后处理:

Tokenizer的预处理
与其他神经网络一样,Transformer 模型无法直接处理原始文本,因此pipeline的第一步是将文本输入转换为模型可以理解的数字。为此,我们使用分词器,它将负责:
- 将输入的文本分词,即拆分为单词、子单词或符号(如标点符号),这些被称为tokens(标记)。
- 将每个token映射到一个整数。
- 添加可能对模型有用的额外输入(微调)。
预训练模型完成后,所有的预处理需要完全相同的方式完成,因此我们首先需要从Model Hub下载该信息。 为此,我们使用 AutoTokenizer 类及其 from_pretrained() 方法。 使用模型的checkpoint,它将自动获取与模型的标记生成器关联的数据并缓存它。
由于情感分析pipeline的checkpoint是 distilbert-base-uncased-finetuned-sst-2-english ,因此我们运行以下命令:
from transformers import AutoTokenizer
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
如此便得到tokenizer对象后,后续只需将文本参数输入即可,便完成了分词-编码-转换工作。
使用Transformers框架不需要担心使用哪个后端 ML 框架(PyTorch、TensorFlow、Flax)。Transformer 模型只接受tensors(张量)作为输入参数。
注:NumPy 数组可以是标量 (0D)、向量 (1D)、矩阵 (2D) 或具有更多维度。它实际上是一个张量。
tokenizer中的return_tensors 参数定了返回的张量类型(PyTorch、TensorFlow 或普通 NumPy)
raw_inputs = [
"I've been waiting for a HuggingFace course my whole life.",
"I hate this so much!",
]
inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt")
print(inputs)
以下是tokenizer返回的PyTorch张量的结果:
{
'input_ids': tensor([
[101, 1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172, 2607, 2026, 2878, 2166, 1012, 102],
[101, 1045, 5223, 2023, 2061, 2172, 999, 102, 0, 0, 0, 0, 0, 0, 0, 0]
]),
'attention_mask': tensor([
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]
])
}
tokenizer的返回值参数说明如下:
- 输出input_ids:经过编码后的数字(即前面所说的张量数据)。
- 输出token_type_ids:因为编码的是两个句子,这个list用于表明编码结果中哪些位置是第1个句子,哪些位置是第2个句子。具体表现为,第2个句子的位置是1,其他位置是0。
- 输出special_tokens_mask:用于表明编码结果中哪些位置是特殊符号,具体表现为,特殊符号的位置是1,其他位置是0。
- 输出attention_mask:用于表明编码结果中哪些位置是PAD。具体表现为,PAD的位置是0,其他位置是1。
- 输出length:表明编码后句子的长度。
Model层的处理
我们可以像使用tokenizer一样下载预训练模型。 Transformers 提供了一个 AutoModel 类,它也有一个 from_pretrained() 方法:
from transformers import AutoModel
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModel.from_pretrained(checkpoint)
## inputs的参数值是前面tokenizer的输出
outputs = model(**inputs)
与初始化tokenizer一样,将相同的checkpoint作为参数,初始化一个Model;而后将tokenizer的输出数据——张量数据作为参数输入到Model中。
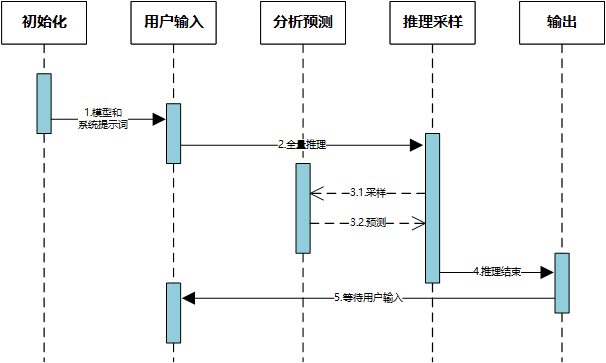
模型的处理架构流程图,如下:
![图片[1]-聊聊HuggingFace Transformer - 玄机博客-玄机博客](https://cdn.nlark.com/yuque/0/2023/svg/28551376/1693101817640-5127b50a-2edd-42be-8da6-ab268b664513.svg#clientId=u2072ad4d-2e1f-4&from=paste&id=u009214c0&originHeight=748&originWidth=1839&originalType=url&ratio=1.75&rotation=0&showTitle=false&status=done&style=none&taskId=u90e1a100-29b4-408f-b22b-c98ebb9f3b7&title=)
Transformer network模块有两层:嵌入层(Embeddings)、后续层(Layers)。嵌入层将标记化输入中的每个输入 ID 转换为表示关联标记的向量。 随后的层使用注意力机制操纵这些向量来产生句子的最终表示。
Transformer的输出,作为Hidden States,也可以理解为是Feature(特征数据)。
而这些特征数据,将作为模型的另一些部分的输入,比如Head层;最终由Head层输出模型的结果。
说起来可能比较抽象,咨询ChatGPT后,其具体的解释如下:
在HuggingFace Transformers库中,Transformer模型由三个主要部分组成:Transformer网络、隐藏状态(hidden states)和”head”部分。让我们逐一解释这三部分的含义和作用:
- Transformer网络:
Transformer网络是一种用于处理序列数据的深度学习架构,特别擅长于捕捉输入序列中的长程依赖关系。它引入了自注意力机制(Self-Attention)和多头注意力机制(Multi-Head Attention),允许模型在不同位置的输入之间建立关联。Transformer模型通常由编码器和解码器组成,但有些任务只使用编码器或解码器。- 隐藏状态(Hidden States):
在Transformer网络中,每个时间步和每个层级都会产生一个隐藏状态。隐藏状态是输入序列在经过模型不同层级和时间步的转换后的中间表示。这些中间表示包含了输入序列的语义和上下文信息。你可以将隐藏状态理解为模型的”内部记忆”,其中包含有关输入数据的编码信息。HuggingFace库允许你从模型的输出中提取这些隐藏状态,以便进一步用于各种任务。- “Head”部分:
在HuggingFace Transformers架构中,”Head”部分指的是模型的顶层网络结构,用于微调(fine-tune)预训练的Transformer模型以适应特定的任务。Head部分通常是特定任务的任务特定层,其设计取决于你要解决的问题类型。
预训练的Transformer模型(如BERT、GPT、RoBERTa等)在大规模的语料库上训练,学习了丰富的语义和上下文信息。然而,这些模型的输出是通用的,不针对具体的任务。为了使预训练的模型适应特定的NLP任务,我们需要添加一个定制的顶层网络,即Head部分。这个Head部分将模型的中间特征映射到任务特定的输出。
Head部分的结构取决于任务的类型。以下是一些示例:
分类任务(Classification): 对于文本分类任务,Head部分通常是一个全连接层,将模型输出的特征映射到分类标签的概率分布。这个全连接层的输出会通过一个softmax函数来计算不同类别的概率。
生成任务(Generation): 对于文本生成任务,如机器翻译或文本摘要,Head部分可能是一个解码器,将模型输出的特征转换为目标语言的文本序列。
序列标注任务(Sequence Labeling): 对于命名实体识别或词性标注等任务,Head部分可能是一系列分类层,分别对每个输入标记进行分类。
回归任务(Regression): 对于回归任务,Head部分可能是一个全连接层,将模型输出的特征映射到连续的目标值。
Head部分将预训练模型的中间特征与特定任务的输出之间建立连接。通过微调整个模型,包括预训练的Transformer部分和任务特定的Head部分,我们可以在特定任务上取得更好的性能。HuggingFace Transformers库提供了预先定义的模型架构和Head部分,使得在不同的NLP任务上进行微调变得更加简单和高效。
在整个流程中,输入数据首先被送入Transformer网络,经过多层的编码和转换,生成隐藏状态。然后,这些隐藏状态被传递到”Head”部分,以生成特定任务的输出。这种模型结构允许在预训练模型的基础上,根据不同任务的需要,对模型进行微调,以提高性能。
综上所述,HuggingFace Transformers库中的模型结构由三部分组成:Transformer网络负责编码输入数据,生成隐藏状态;隐藏状态是输入数据的中间表示,包含语义和上下文信息;”Head”部分用于根据任务需求将隐藏状态映射到输出。这种结构允许模型从预训练状态逐步适应各种NLP任务。
Transformer network网络层的解释如下:
在Hugging Face Transformers库中,Transformer模型的layers层通常指的是整个Transformer架构中的堆叠层,包括编码器(Encoder)和解码器(Decoder)层(如果是Seq2Seq模型),或者只包括编码器层(如果是用于分类或回归等任务的模型)。
这些layers包含了多个重要组件,如自注意力层、前馈神经网络层、残差连接、层归一化等,通常的层级结构如下:
多个编码器层(Encoder Layers): 这些层堆叠在一起,每个编码器层包括自注意力层和前馈神经网络层。编码器的作用是将输入序列编码成上下文表示。
解码器层(Decoder Layers,仅适用于Seq2Seq模型): 如果模型是Seq2Seq类型的,例如用于机器翻译,那么除了编码器层外,还包括解码器层。解码器层通常包括自注意力层、编码器-解码器注意力层和前馈神经网络层。解码器的作用是生成目标序列。
残差连接和层归一化: 在每个编码器和解码器层中,通常都会使用残差连接和层归一化来增强模型的训练稳定性和性能。
位置编码: 位置编码通常被添加到输入中以提供位置信息。
这些层的数量可以根据具体的Transformer模型架构和任务来变化。例如,BERT模型只包括编码器层,而GPT模型只包括解码器层。整个layers部分构成了Transformer模型的核心结构,它负责处理输入序列并生成适合特定任务的输出。不同的Transformer模型和架构会在layers的组成和层数方面有所不同。
总结
如上概述了HuggingFace Transformer相关的项目组件及背景逻辑,比较基础,蛮重要的,这些相关的基础点都是通用的。在理解大模型与NLP上都是相辅相成。
1.本站内容仅供参考,不作为任何法律依据。用户在使用本站内容时,应自行判断其真实性、准确性和完整性,并承担相应风险。
2.本站部分内容来源于互联网,仅用于交流学习研究知识,若侵犯了您的合法权益,请及时邮件或站内私信与本站联系,我们将尽快予以处理。
3.本文采用知识共享 署名4.0国际许可协议 [BY-NC-SA] 进行授权
4.根据《计算机软件保护条例》第十七条规定“为了学习和研究软件内含的设计思想和原理,通过安装、显示、传输或者存储软件等方式使用软件的,可以不经软件著作权人许可,不向其支付报酬。”您需知晓本站所有内容资源均来源于网络,仅供用户交流学习与研究使用,版权归属原版权方所有,版权争议与本站无关,用户本人下载后不能用作商业或非法用途,需在24个小时之内从您的电脑中彻底删除上述内容,否则后果均由用户承担责任;如果您访问和下载此文件,表示您同意只将此文件用于参考、学习而非其他用途,否则一切后果请您自行承担,如果您喜欢该程序,请支持正版软件,购买注册,得到更好的正版服务。
5.本站是非经营性个人站点,所有软件信息均来自网络,所有资源仅供学习参考研究目的,并不贩卖软件,不存在任何商业目的及用途












暂无评论内容