
本文首先分析微调脚本trainer.sh的内容,再剖析ChatGLM是如何与Huggingface平台对接,实现transformers库的API直接调用ChatGLM模型,最后定位到了ChatGLM模型的源码文件。
脚本分析
微调脚本:
PRE_SEQ_LEN=128
LR=2e-2
CUDA_VISIBLE_DEVICES=0 python3 main.py \
--do_train \
--train_file AdvertiseGen/train.json \
--validation_file AdvertiseGen/dev.json \
--prompt_column content \
--response_column summary \
--overwrite_cache \
--model_name_or_path THUDM/chatglm-6b \
--output_dir output/adgen-chatglm-6b-pt-$PRE_SEQ_LEN-$LR \
--overwrite_output_dir \
--max_source_length 64 \
--max_target_length 64 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 16 \
--predict_with_generate \
--max_steps 3000 \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate $LR \
--pre_seq_len $PRE_SEQ_LEN \
--quantization_bit 4
脚本配置项分析:
PRE_SEQ_LEN=128: 定义了序列长度为128。这个参数通常用于设置输入序列的最大长度。LR=2e-2: 定义了学习率为0.02。学习率是模型训练中的一个重要超参数,它决定了模型参数更新的幅度。CUDA_VISIBLE_DEVICES=0: 这个环境变量用于设置哪些GPU将被TensorFlow框架使用。在这个脚本中,只使用了第一个GPU(索引为0)。python3 main.py: 这一行开始执行主训练脚本main.py。--do_train: 这个标志告诉脚本执行训练过程。--prompt_column content: 这个标志指定了输入列的名称,这里称为content。这是模型接收的输入列的名称。--response_column summary: 这个标志指定了输出列的名称,这里称为summary。这是模型需要生成的输出列的名称。--model_name_or_path THUDM/ChatGLM-6b: 这个标志指定了预训练模型的名称或路径。这里使用的是名为THUDM/ChatGLM-6b的预训练模型。--output_dir output/adgen-ChatGLM-6b-pt-$PRE_SEQ_LEN-$LR: 这个标志指定了输出目录。目录名为output/adgen-ChatGLM-6b-pt-128-0.02,其中128和0.02分别由$PRE_SEQ_LEN和$LR变量替换。--per_device_train_batch_size 1: 这个标志设置了每个设备上的训练批次大小为1。--per_device_eval_batch_size 1: 这个标志设置了每个设备上的评估批次大小为1。--gradient_accumulation_steps 16: 这个标志设置了梯度累积的步数为16。这意味着在每个更新步骤中,会将最近16个步骤的梯度相加。--max_steps 3000: 这个标志设置了训练过程中的最大步数为3000。--save_steps 1000: 这个标志设置了保存模型检查点的步数为1000。这意味着每1000个步骤后,将保存一次模型的状态。--learning_rate $LR: 这个标志设置了学习率为之前定义的LR变量(0.02)。--pre_seq_len $PRE_SEQ_LEN: 这个标志设置了序列长度为之前定义的PRE_SEQ_LEN变量(128)。
在官方的微调文档中,用的是ADGEN数据集,其格式也就是上述的--prompt_column content和--response_column summary配置项决定的。而最终保存在output_dir配置项指定的目录下有多个checkpoint文件,其生成频率就是由save_steps配置项决定。
main.py
main文件中,依赖了trainer_seq2seq.py,而这又依赖了trainer.py文件。trainer.py文件则是直接copy自transformers库的同名文件。
transformers库的
目前的大模型都会对接到transformers库中,通过transformers库简化调用开发。AI模型的对接,遵循HuggingFace平台的要求。整个ChatGLM系列的推理、训练、微调都可以直接调用transformers库的API。常用的是如下三句:
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
huggingface平台与ChatGLM
在ChatGLM的部署过程中,需要在huggingface平台上下载模型参数以及配置初始化文件。而这些配置文件,transformers库的API能够调用的原因。
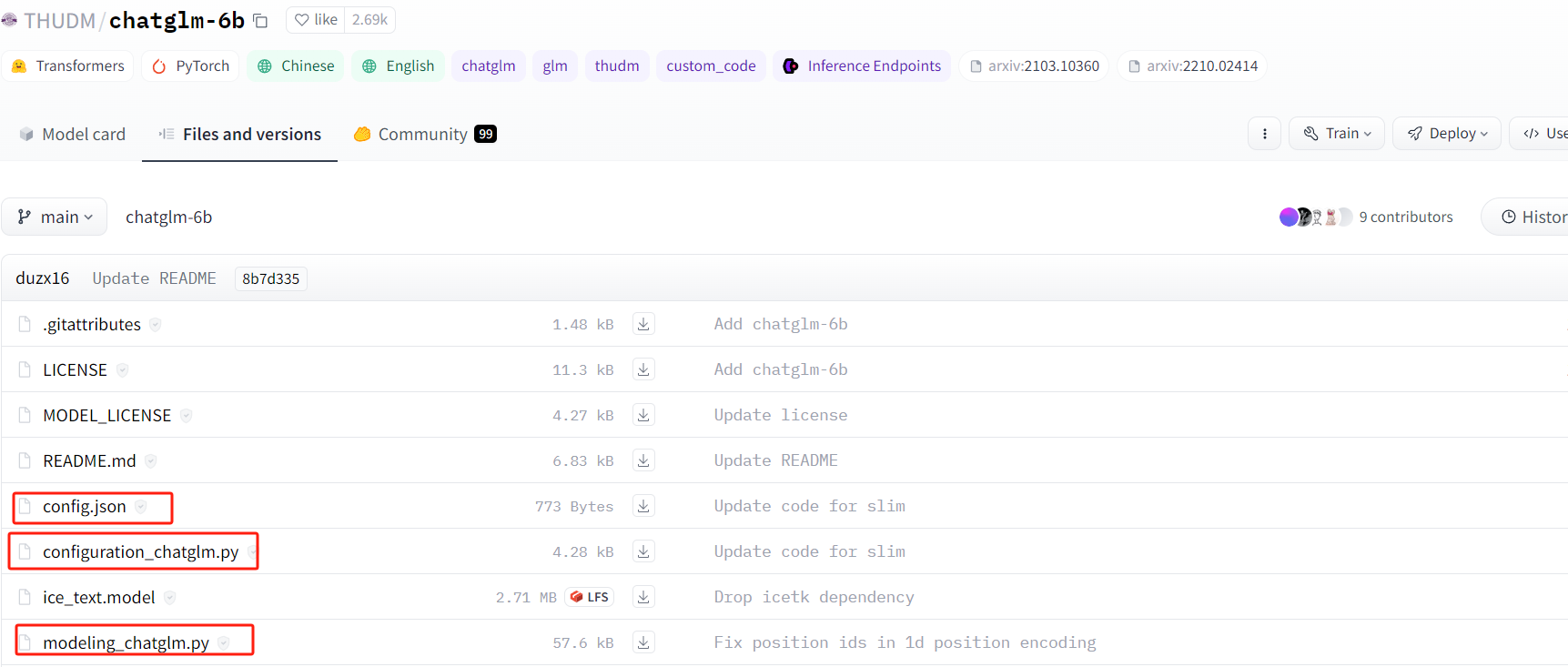
![图片[1]-聊聊ChatGLM6B的微调脚本及与Huggingface的关联 - 玄机博客-玄机博客](https://img2024.cnblogs.com/blog/971683/202401/971683-20240104105504824-854394171.png)
![图片[2]-聊聊ChatGLM6B的微调脚本及与Huggingface的关联 - 玄机博客-玄机博客](https://img2024.cnblogs.com/blog/971683/202401/971683-20240104105504769-1247590469.png)
比较重要的,就是圈出来的三个。config.json文件中,配置了模型的基本信息以及transformers API的调用关系:
{
"_name_or_path": "THUDM/chatglm-6b",
"architectures": [
"ChatGLMModel"
],
"auto_map": {
"AutoConfig": "configuration_chatglm.ChatGLMConfig",
"AutoModel": "modeling_chatglm.ChatGLMForConditionalGeneration",
"AutoModelForSeq2SeqLM": "modeling_chatglm.ChatGLMForConditionalGeneration"
},
"bos_token_id": 130004,
"eos_token_id": 130005,
"mask_token_id": 130000,
"gmask_token_id": 130001,
"pad_token_id": 3,
"hidden_size": 4096,
"inner_hidden_size": 16384,
"layernorm_epsilon": 1e-05,
"max_sequence_length": 2048,
"model_type": "chatglm",
"num_attention_heads": 32,
"num_layers": 28,
"position_encoding_2d": true,
"torch_dtype": "float16",
"transformers_version": "4.23.1",
"use_cache": true,
"vocab_size": 130528
}
如上的auto_map配置项。configuration_chatglm文件是该config文件的类表现形式。
modeling_chatglm.py文件是源码文件,ChatGLM对话模型的所有源码细节都在该文件中。我之前一直没找到ChatGLM的源码,就是神经网络的相关代码,经过一波的分析,终于是定位到了。所以在config文件中会配置AutoModel API直接取调用modeling_chatglm.ChatGLMForConditionalGeneration。
1.本站内容仅供参考,不作为任何法律依据。用户在使用本站内容时,应自行判断其真实性、准确性和完整性,并承担相应风险。
2.本站部分内容来源于互联网,仅用于交流学习研究知识,若侵犯了您的合法权益,请及时邮件或站内私信与本站联系,我们将尽快予以处理。
3.本文采用知识共享 署名4.0国际许可协议 [BY-NC-SA] 进行授权
4.根据《计算机软件保护条例》第十七条规定“为了学习和研究软件内含的设计思想和原理,通过安装、显示、传输或者存储软件等方式使用软件的,可以不经软件著作权人许可,不向其支付报酬。”您需知晓本站所有内容资源均来源于网络,仅供用户交流学习与研究使用,版权归属原版权方所有,版权争议与本站无关,用户本人下载后不能用作商业或非法用途,需在24个小时之内从您的电脑中彻底删除上述内容,否则后果均由用户承担责任;如果您访问和下载此文件,表示您同意只将此文件用于参考、学习而非其他用途,否则一切后果请您自行承担,如果您喜欢该程序,请支持正版软件,购买注册,得到更好的正版服务。
5.本站是非经营性个人站点,所有软件信息均来自网络,所有资源仅供学习参考研究目的,并不贩卖软件,不存在任何商业目的及用途












暂无评论内容