
从零入门AI生图原理&实践是 Datawhale 2024 年 AI 夏令营第四期的学习活动(“AIGC”方向),基于魔搭社区“可图Kolors-LoRA风格故事挑战赛”开展的实践学习——
- 适合想 入门并实践 AIGC文生图、工作流搭建、LoRA微调 的学习者参与
学习内容提要:从通过代码实现AI文生图逐渐进阶,教程偏重图像工作流、微调、图像优化等思路,最后会简单介绍AIGC应用方向、数字人技术(选学)
Datawhale学习手册置顶=>从零入门AI生图原理&实践
1. 赛题任务概述
参赛链接:可图Kolors-LoRA风格故事挑战赛
赛事目标:
- 参赛者需在可图Kolors 模型的基础上训练LoRA 模型,生成无限风格,如水墨画风格、水彩风格、赛博朋克风格、日漫风格……
- 基于LoRA 模型生成 8 张图片组成连贯故事,故事内容可自定义;基于8图故事,评估LoRA风格的美感度及连贯性 样例:偶像少女养成日记
赛事流程:
- 初赛:报名后-2024年8月31日23:59
- 决赛:2024年9月5日答辩展示,线上决出一二三等奖(评委主观评分)
2. task01-跑通baseline
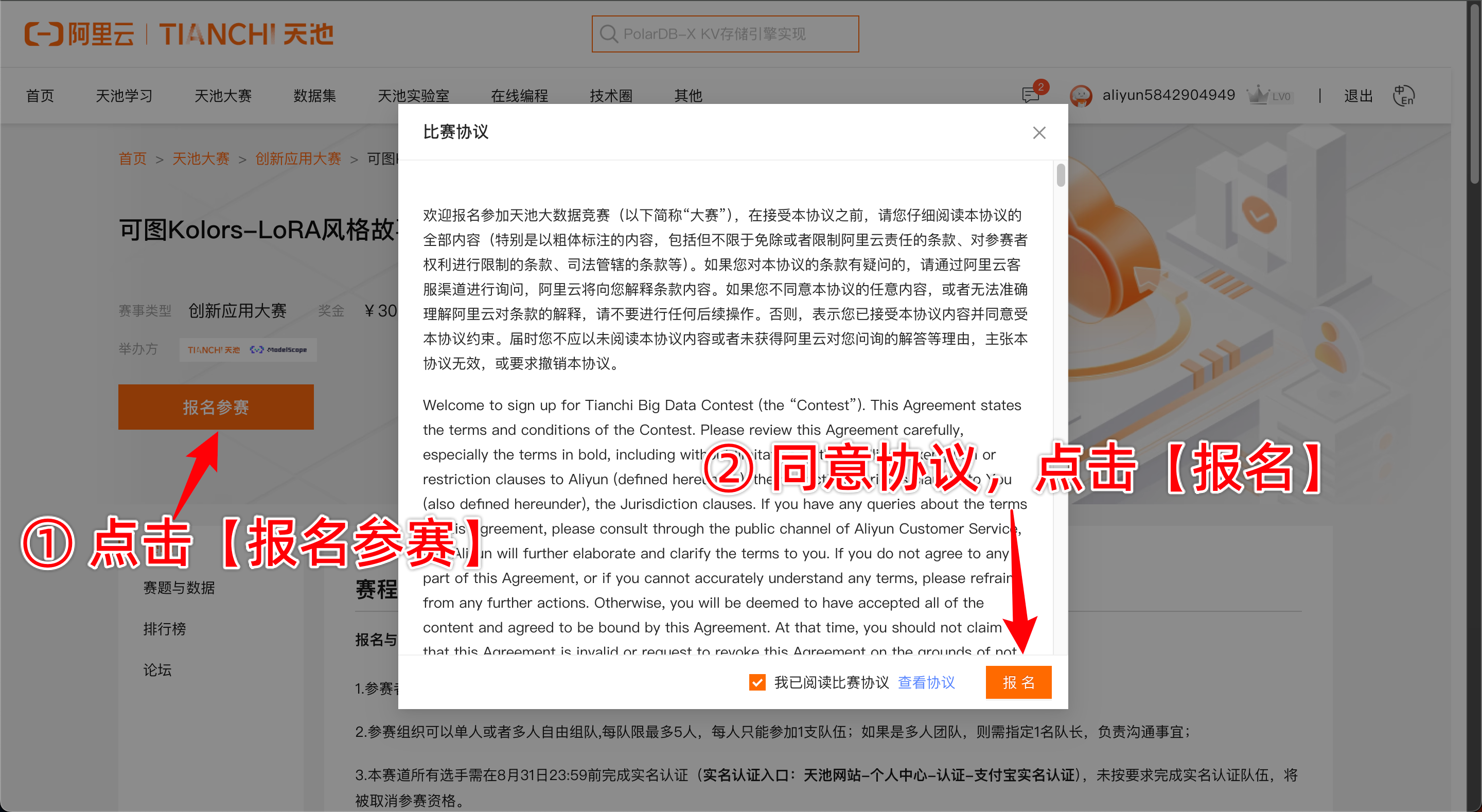
2.1 比赛报名
点击参赛链接,同意协议后即可报名成功。

2.2 创建阿里云PAI-DSW实例
每个新用户都有一个免费试用的机会=>阿里云免费试用链接
![图片[1]-Datawhale X 魔搭 2024年AI夏令营第四期AIGC方向 Task01 - 玄机博客-玄机博客](https://img2024.cnblogs.com/blog/2716953/202408/2716953-20240811103220603-1652399824.png)
![图片[2]-Datawhale X 魔搭 2024年AI夏令营第四期AIGC方向 Task01 - 玄机博客-玄机博客](https://img2024.cnblogs.com/blog/2716953/202408/2716953-20240811103248866-1351499027.png)
注意事项:
- 第③步务必选择第二个, 第一个的GPU的显存不够
- 如果创建后未找到实例,可能是现有的实例和新创建的实例不在同一地区,请点击新建实例上方的地区(图中为华东1(杭州))进行切换
2.3 baseline下载
git lfs install
git clone https://www.modelscope.cn/datasets/maochase/kolors.git
![图片[3]-Datawhale X 魔搭 2024年AI夏令营第四期AIGC方向 Task01 - 玄机博客-玄机博客](https://img2024.cnblogs.com/blog/2716953/202408/2716953-20240811104312908-1124964107.png)

2.4 baseline部分代码解读
保存数据集中的图片及元数据
os.makedirs("./data/lora_dataset/train", exist_ok=True)
os.makedirs("./data/data-juicer/input", exist_ok=True)
with open("./data/data-juicer/input/metadata.jsonl", "w") as f:
for data_id, data in enumerate(tqdm(ds)):
image = data["image"].convert("RGB")
image.save(f"/mnt/workspace/kolors/data/lora_dataset/train/{data_id}.jpg")
metadata = {"text": "二次元", "image": [f"/mnt/workspace/kolors/data/lora_dataset/train/{data_id}.jpg"]}
f.write(json.dumps(metadata))
f.write("\n")
我们将数据集保存为(text, image)的数据对并存储在jsonl文件中
(JSONL文件(JSON Lines)是一种每行包含一个独立的 JSON 对象的文本文件格式。每行都是一个有效的 JSON 对象,使用换行符分隔)
![图片[4]-Datawhale X 魔搭 2024年AI夏令营第四期AIGC方向 Task01 - 玄机博客-玄机博客](https://img2024.cnblogs.com/blog/2716953/202408/2716953-20240811105150977-707943807.png)
其中text的中文”二次元”是用Unicode编码存储的
模型加载
# Load models
model_manager = ModelManager(
torch_dtype=torch.float16,
device="cuda",
file_path_list=[
"models/kolors/Kolors/text_encoder",
"models/kolors/Kolors/unet/diffusion_pytorch_model.safetensors",
"models/kolors/Kolors/vae/diffusion_pytorch_model.safetensors"
])
pipe = SDXLImagePipeline.from_model_manager(model_manager)
模型使用半精度浮点数(torch.float16),并指定了文本编码器、UNet 模型和 VAE 模型的权重文件
load_lora 函数
def load_lora(model, lora_rank, lora_alpha, lora_path):
lora_config = LoraConfig(
r=lora_rank,
lora_alpha=lora_alpha,
init_lora_weights="gaussian",
target_modules=["to_q", "to_k", "to_v", "to_out"],
)
model = inject_adapter_in_model(lora_config, model)
state_dict = torch.load(lora_path, map_location="cpu")
model.load_state_dict(state_dict, strict=False)
return model
- lora_rank: LoRA 中低秩矩阵的秩,决定了适配器的容量
- lora_alpha: LoRA 的缩放因子,控制适配器的影响力
- init_lora_weights:LoRA 适配器权重的初始化方法
- target_modules:指定模型中的子模块注入 LoRA 适配器。通常是与注意力机制相关的层,如这里的to_q、to_k、to_v 和 to_out
- inject_adapter_in_model:将 LoRA 适配器注入到模型中
2.5 prompt修改技巧
首先列出最希望图像中包含的核心元素(如风格,主要人物),把次要的细节或补充描述放在句子的后面,这样模型会先生成主元素,再填充细节。
以baseline中图二的prompt为例:

如果我们把主次交换后会出现什么情况?
 图二 原始prompt 图二 原始prompt |
 图二 修改prompt 图二 修改prompt |
修改prompt:二次元,日系动漫,演唱会的舞台上衣着华丽的歌星们在唱歌,演唱会的观众席,人山人海,一个紫色短发小女孩穿着粉色吊带漏肩连衣裙坐在演唱会的观众席
由于主体信息的后移,主体信息将次体信息当作了背景信息,最终产生了主次融合后的结果
2.6 生成的一些结果
 |
 |
 |
对于单个人物,由于有详细的描述可以达到较好的结果。但是对于群像图来说,因为我提供的prompt有限,生成的较为粗糙。
3.相关知识学习推荐

对于文生图的发展,我们不必从头开始了解所有技术的详细过程,但是大致知道技术是如何发展的有助于我们更高的理解模型。
在DALL·E 2(内含扩散模型介绍)【论文精读】中,会介绍从GAN,到VAE,VQVAE,再到现在普遍使用的扩散模型(Diffusion)的技术改进思想(视频从28:00开始),十分推荐观看!
1.本站内容仅供参考,不作为任何法律依据。用户在使用本站内容时,应自行判断其真实性、准确性和完整性,并承担相应风险。
2.本站部分内容来源于互联网,仅用于交流学习研究知识,若侵犯了您的合法权益,请及时邮件或站内私信与本站联系,我们将尽快予以处理。
3.本文采用知识共享 署名4.0国际许可协议 [BY-NC-SA] 进行授权
4.根据《计算机软件保护条例》第十七条规定“为了学习和研究软件内含的设计思想和原理,通过安装、显示、传输或者存储软件等方式使用软件的,可以不经软件著作权人许可,不向其支付报酬。”您需知晓本站所有内容资源均来源于网络,仅供用户交流学习与研究使用,版权归属原版权方所有,版权争议与本站无关,用户本人下载后不能用作商业或非法用途,需在24个小时之内从您的电脑中彻底删除上述内容,否则后果均由用户承担责任;如果您访问和下载此文件,表示您同意只将此文件用于参考、学习而非其他用途,否则一切后果请您自行承担,如果您喜欢该程序,请支持正版软件,购买注册,得到更好的正版服务。
5.本站是非经营性个人站点,所有软件信息均来自网络,所有资源仅供学习参考研究目的,并不贩卖软件,不存在任何商业目的及用途









暂无评论内容