

自然语言处理概述
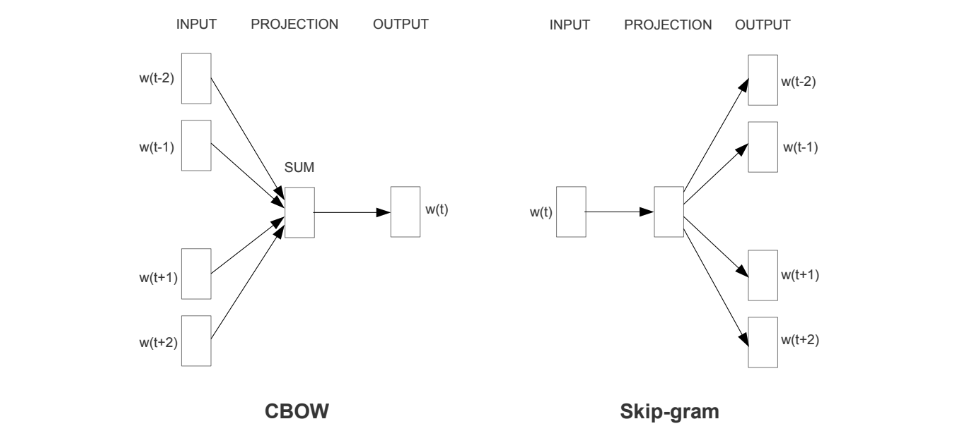
以前的自然语言大多数停留在去根据业务来编写相应的规则来解决实际的问题,但是仅仅靠手工编写的规则是无法覆盖全部的内容,而且不同的规则之间也具有一定的矛盾,随着统计学的发展,人们逐渐的用统计的思想去解决一些实际的问题,例如马尔可夫假设,即一个词语出现的概率取决于它前面出现的所有词,但是随着文本长度的增加,对应条件概率的计算也变得困难。随着神经网络的发展,在2013年时,Google提出Word2Vec,这个模型是所有NLP学习者都熟悉的模型,他分为CBOW和Skip-gram两种,其中CBOW是使用周围的词语来进行预测中间的词,Skip-gram则是通过中间词来预测周围的词,但是该模型无法处理一词多义的问题,后面LSTM和CNN等模型也相继出现,来对句子中的词语进行编码,以便捕获词语的上下文的信息。
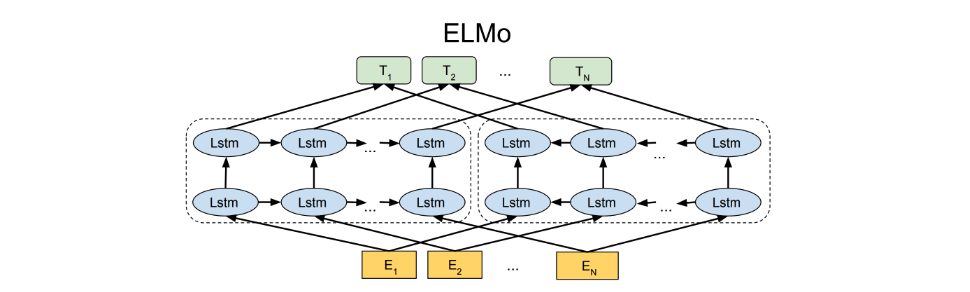
2018年ELMO的出现,直接在词向量给出了一种优雅的解决方案,使用双向的LSTM作为网络结构,从两个方向编码词语的上下文来进行预测,该模型基于LSTM作为编码器,而不是特征提取能力更强的Transformer。
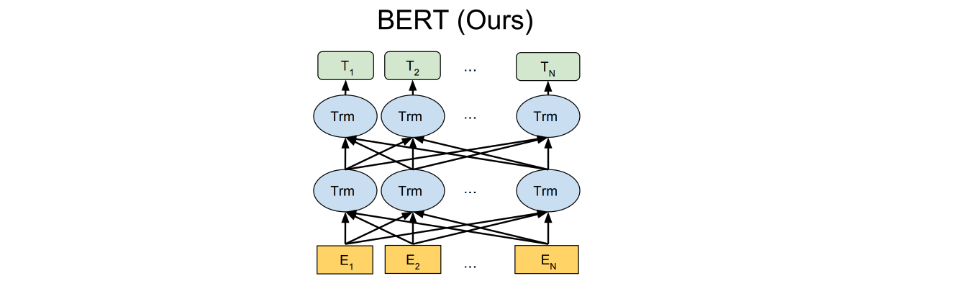
随后GPT将ELMO中的LSTM替换为Transformer,GPT根据上文来进行下文的预测,但是没有考虑下文的信息,在一些任务上适应性较差,比如阅读理解,后面划时代的BERT出现,在编码方面不仅采用Transformer作为编码器,而且在预训练阶段采用NSP和MLM进行训练,使得词语的信息具有上下文的信息,使得更多的下游任务,后面BERT的变种陆续的出现,例如MacBert、RoBERTa和Ernie等。
时至今日,大模型也逐渐的发展起来,现有开源的大模型无法处理特有的场景,所以很多企业结合自己的知识库,来对问题进行相关的检索,让大模型进行检索结果的总结,到这里自然语言的概述就写完了,后面对不断的更新所学内容。
1.本站内容仅供参考,不作为任何法律依据。用户在使用本站内容时,应自行判断其真实性、准确性和完整性,并承担相应风险。
2.本站部分内容来源于互联网,仅用于交流学习研究知识,若侵犯了您的合法权益,请及时邮件或站内私信与本站联系,我们将尽快予以处理。
3.本文采用知识共享 署名4.0国际许可协议 [BY-NC-SA] 进行授权
4.根据《计算机软件保护条例》第十七条规定“为了学习和研究软件内含的设计思想和原理,通过安装、显示、传输或者存储软件等方式使用软件的,可以不经软件著作权人许可,不向其支付报酬。”您需知晓本站所有内容资源均来源于网络,仅供用户交流学习与研究使用,版权归属原版权方所有,版权争议与本站无关,用户本人下载后不能用作商业或非法用途,需在24个小时之内从您的电脑中彻底删除上述内容,否则后果均由用户承担责任;如果您访问和下载此文件,表示您同意只将此文件用于参考、学习而非其他用途,否则一切后果请您自行承担,如果您喜欢该程序,请支持正版软件,购买注册,得到更好的正版服务。
5.本站是非经营性个人站点,所有软件信息均来自网络,所有资源仅供学习参考研究目的,并不贩卖软件,不存在任何商业目的及用途









暂无评论内容