

这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助

一、故事的开始
最近产品又开始整活了,本来是毫无压力的一周,可以小摸一下鱼的,但是突然有一天跟我说要做一个在网页端截屏的功能。
作为一个工作多年的前端,早已学会了尽可能避开麻烦的需求,只做增删改查就行!
我立马开始了我的反驳,我的理由是市面上截屏的工具有很多的,微信截图、Snipaste都可以做到的,自己实现的话,一是比较麻烦,而是性能也不会很好,没有必要,把更多的时间放在核心业务更合理!
结果产品跟我说因为公司内部有个可以用来解析图片,生成文本OCR的算法模型,web端需要支持截取网页中部分然后交给模型去训练,微信以及其他的截图工具虽然可以截图,但需要先保存到本地,再上传给模型才行。
网页端支持截图后可以在在截屏的同时直接上传给模型,减少中间过程,提升业务效率。
我一听这产品小嘴巴巴的说的还挺有道理,没有办法,只能接了这个需求,从此命运的齿轮开始转动,开始了我漫长而又曲折的思考。
二、我的思考
在实现任何需求的时候,我都会在自己的脑子中大概思考一下,评估一下它的难度如何。我发现web端常见的需求是在一张图片上截图,这个还是比较容易的,只需要准备一个canvas,然后利用canvas的方法 drawImage就可以截取这个图片的某个部分了。
示例如下:
<!DOCTYPE html>
<html>
<head>
<title>截取图片部分示例</title>
</head>
<body>
<canvas id="myCanvas" width="400" height="400"></canvas>
<br>
<button onclick="cropImage()">截取图片部分</button>
<br>
<img id="croppedImage" alt="截取的图片部分">
<br>
<script>
function cropImage() {
var canvas = document.getElementById('myCanvas');
var ctx = canvas.getContext('2d');
var image = new Image();
image.onload = function () {
// 在canvas上绘制整张图片
ctx.drawImage(image, 0, 0, canvas.width, canvas.height);
// 截取图片的一部分,这里示例截取左上角的100x100像素区域
var startX = 0;
var startY = 0;
var width = 100;
var height = 100;
var croppedData = ctx.getImageData(startX, startY, width, height);
// 创建一个新的canvas用于显示截取的部分
var croppedCanvas = document.createElement('canvas');
croppedCanvas.width = width;
croppedCanvas.height = height;
var croppedCtx = croppedCanvas.getContext('2d');
croppedCtx.putImageData(croppedData, 0, 0);
// 将截取的部分显示在页面上
var croppedImage = document.getElementById('croppedImage');
croppedImage.src = croppedCanvas.toDataURL();
};
// 设置要加载的图片
image.src = 'your_image.jpg'; // 替换成你要截取的图片的路径
}
</script>
</body>
</html>
一、获取像素的思路
但是目前的这个需求远不止这样简单,因为它的对象是整个document,需要在整个document上截取一部分,我思考了一下,其实假设如果浏览器为我们提供了一个api,能够获取到某个位置的像素信息就好了,这样我将选定的某个区域的每个像素信息获取到,然后在一个像素一个像素绘制到canvas上就好了。
我本以为我发现了一个很好的方法,可遗憾的是经过调研浏览器并没有为我们提供类似获取某个位置像素信息的API。
唯一为我们提供获取像素信息的是canvas的这个API。
<!DOCTYPE html>
<html>
<head>
<title>获取特定像素信息示例</title>
</head>
<body>
<canvas id="myCanvas" width="400" height="400"></canvas>
<br>
<button onclick="getPixelInfo()">获取特定像素信息</button>
<br>
<div id="pixelInfo"></div>
<script>
function getPixelInfo() {
var canvas = document.getElementById('myCanvas');
var ctx = canvas.getContext('2d');
// 绘制一些内容到canvas
ctx.fillStyle = 'red';
ctx.fillRect(50, 50, 100, 100);
// 获取特定位置的像素信息
var x = 75; // 替换为你想要获取的像素的x坐标
var y = 75; // 替换为你想要获取的像素的y坐标
var pixelData = ctx.getImageData(x, y, 1, 1).data;
// 提取像素的颜色信息
var red = pixelData[0];
var green = pixelData[1];
var blue = pixelData[2];
var alpha = pixelData[3];
// 将信息显示在页面上
var pixelInfo = document.getElementById('pixelInfo');
pixelInfo.innerHTML = '在位置 (' + x + ', ' + y + ') 的像素信息:<br>';
pixelInfo.innerHTML += '红色 (R): ' + red + '<br>';
pixelInfo.innerHTML += '绿色 (G): ' + green + '<br>';
pixelInfo.innerHTML += '蓝色 (B): ' + blue + '<br>';
pixelInfo.innerHTML += 'Alpha (透明度): ' + alpha + '<br>';
}
</script>
</body>
</html>
浏览器之所以没有为我们提供相应的API获取像素信息,停下来想想也是有道理的,甚至是必要的,因为假设浏览器为我们提供了这个API,那么恶意程序就可以通过这个API,不断的获取你的浏览器页面像素信息,然后全部绘制出来。一旦你的浏览器运行这个段恶意程序,那么你在浏览器干的什么,它会一览无余,相当于在网络的世界里裸奔,毫无隐私可言。
二、把DOM图片化
既然不能走捷径直接拿取像素信息,那就得老老实实的把document转换为图片,然后调用canvas的drawImage这个方法来截取图片了。
在前端领域其实99%的业务场景早已被之前的大佬们都实现过了,相应的轮子也很多。我问了一下chatGPT,它立马给我推荐了大名鼎鼎的html2canvas,这个库能够很好的将任意的dom转化为canvas。这个是它的官网。
我会心一笑,因为这不就直接能够实现需求了,很容易就可以写出下面的代码了:
html2canvas(document.body).then(function(canvas) {
// 将 Canvas 转换为图片数据URL
var src = canvas.toDataURL("image/png");
var image = new Image();
image.src = src;
image.onload = ()=>{
const canvas = document.createElement("canvas")
const ctx = canvas.getContext("2d");
const width = 100;
const height = 100;
canvas.width = width;
canvas.height = height;
// 截取以(10,10)为顶点,长为100,宽为100的区域
ctx.drawImage(image, 10, 10, width, height , 0 , 0 ,width , height);
}
});
上面这段代码就可以实现截取document的特定的某个区域,需求已经实现了,但是我看了一下这个html2canvas库的资源发现并没有那么简单,有两个点并不满足我希望实现的点:
1.大小
当我们将html2canvas引入我们的项目的时候,即便压缩过后,它的资源也有近200kb:
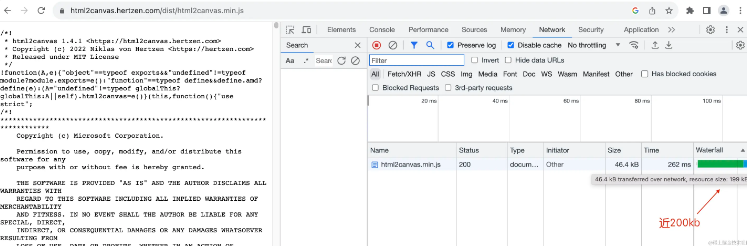
要知道整个react和react-dom的包压缩过后也才不到150kb,因此在项目只为了一个单一的功能引入一个复杂的资源可能并不划算,引入一个复杂度高的包一个是它会增加构建的时间,另一方面也会增加打包之后的体积。
如果是普通的web工程可能情有可原,但是因为我会将这需求做到插件当中,插件和普通的web不一样的一点,就是web工程如果更新之后,客户端是自动更新的。但是插件如果更新了,需要客户端手动的下载插件包,然后再在浏览器安装,因此包的大小尽可能小才好,如果一个插件好几十MB的话,那客户端肯定烦死了。
2.性能
作为业内知名的html2canvas库,性能方面表现如何呢?
我们可以看看它的原理,一个dom结构是如何变成一个canvas的呢!
它的源码在这里:核心的实现是canvas-renderer.ts这个文件。
当html2canvas拿到dom结构之后,首先为了避免副作用给原dom造成了影响,它会克隆一份全新的dom,然后遍历DOM的每一个节点,将其扁平化,这个过程中会收集每个节点的样式信息,尤其是在界面上的布局的几何信息,存入一个栈中。
然后再遍历栈中的每一个节点进行绘制,根据之前收集的样式信息进行绘制,就这样一点点的绘制到提前准备的和传入dom同样大小的canvas当中,由于针对很多特殊的元素,都需要处理它的绘制逻辑,比如iframe、input、img、svg等等。所以整个代码就比较多,自然大小就比较大了。
整个过程其实需要至少3次对整个dom树的遍历才可以绘制出来一个canvas的实例。
这个就是这个绘制类的主要实现方法:

可以看到,它需要考虑的因素确实特别多,类似写这个浏览器的绘制引擎一样,特别复杂。
要想解决以上的大小的瓶颈。
第一个方案就是可以将这个资源动态加载,但是一旦动态加载就不能够在离线的环境下使用,在产品层面是不能接受的,因为大家可以想一想如果微信截图的功能在没有网络的时候就使用不了,这个肯定不正常,一般具备工具属性的功能应该尽可能可以做到离线使用,这样才好。
因此相关的代码资源不能够动态加载。
dom-to-image
正当我不知道如何解决的时候,我发现另外了一个库dom-to-image,我发现它打包后的大小只有10kb左右,这其实已经一个很可以接受的体积了。这个是它的github主页。好奇的我想知道它是怎么做到只有这么小的体积就能够实现和html2canvas几乎同样的功能的呢?于是我就研究了一下它的实现。
dom-to-image的实现利用了一个非常灵活的特性–image可以渲染svg。
我们可以复习一下img标签的src可以接受什么样的类型:这里是mdn的说明文档:
可以接受的格式要求是:
- APNG(动态可移植网络图形)——无损动画序列的不错选择(GIF 性能较差)。
- AVIF(AV1 图像文件格式)——静态图像或动画的不错选择,其性能较好。
- GIF(图像互换格式)——简单图像和动画的不错选择。
- JPEG(联合图像专家组)——有损压缩静态图像的不错选择(目前最流行的格式)。
- PNG(便携式网络图形)——对于无损压缩静态图像而言是不错的选择(质量略好于 JPEG)。
- SVG(可缩放矢量图形)——矢量图像格式。用于必须以不同尺寸准确描绘的图像。
- WebP(网络图片格式)——图像和动画的绝佳选择。
如果我们使用svg格式来渲染图片就可以是这样的方式:
<!DOCTYPE html>
<html>
<head>
<title>渲染SVG</title>
</head>
<body>
<h1>SVG示例</h1>
<img src="example.svg" alt="SVG示例">
</body>
</html>
但是也可以是这样的方式:
<!DOCTYPE html>
<html>
<head>
<title>渲染SVG字符串</title>
</head>
<body>
<div id="svg-container">
<!-- 这里是将SVG内容渲染到<img>标签中 -->
<img id="svg-image" src="data:image/svg+xml, <svg xmlns='http://www.w3.org/2000/svg' width='100' height='100'><circle cx='50' cy='50' r='40' stroke='black' stroke-width='2' fill='red' /></svg>" alt="SVG图像">
</div>
</body>
</html>
把svg的标签序列化之后直接放在src属性上,image也是可以成功解析的,只不过我们需要添加一个头部:data:image/svg+xml, 。
令人兴奋的是,svg并不是只支持svg语法,也支持将其他的xml类型的语法比如html嵌入在其中。antv的x6组件中有非常多这样的应用例子,我给大家截图看一下:
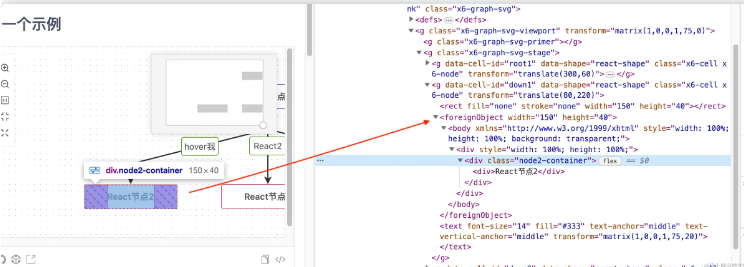
在svg中可以通过foreignObject这个标签来嵌套一些其他的xml语法,比如html等,有了这一特性,我们就可以把上面的例子改造一下:
<!DOCTYPE html>
<html>
<head>
<title>渲染SVG字符串</title>
</head>
<body>
<div id="svg-container">
<!-- 这里是将SVG内容渲染到<img>标签中 -->
<img
id="svg-image"
src="data:image/svg+xml, <svg xmlns='http://www.w3.org/2000/svg' width='100' height='100'><circle cx='50' cy='50' r='40' stroke='black' stroke-width='2' fill='red' /><foreignObject>{ 中间可以放 dom序列化后的结果呀 }</foreignObject></svg>"
alt="SVG图像"
>
</div>
</body>
</html>
所以我们可以将dom序列化后的结构插到svg中,这不就天然的形成了一种dom->image的效果么?下面是演示的效果:
<!DOCTYPE html>
<html>
<head>
<title>渲染SVG字符串</title>
</head>
<body>
<div id="render" style="width: 100px; height: 100px; background: red"></div>
<br />
<div id="svg-container">
<!-- 这里是将SVG内容渲染到<img>标签中 -->
<img id="svg-image" alt="SVG图像" />
</div>
<script>
const perfix =
"data:image/svg+xml;charset=utf-8,<svg xmlns='http://www.w3.org/2000/svg' width='100' height='100'><foreignObject x='0' y='0' width='100%' height='100%'>";
const surfix = "</foreignObject></svg>";
const render = document.getElementById("render");
render.setAttribute("xmlns", "http://www.w3.org/1999/xhtml");
const string = new XMLSerializer()
.serializeToString(render)
.replace(/#/g, "%23")
.replace(/\n/g, "%0A");
const image = document.getElementById("svg-image");
const src = perfix + string + surfix;
console.log(src);
image.src = src;
</script>
</body>
</html>

如果你将这个字符串直接通过浏览器打开,也是可以的,说明浏览器可以直接识别这种形式的媒体资源正确解析对应的资源:
data:image/svg+xml;charset=utf-8,<svg xmlns='http://www.w3.org/2000/svg' width='100' height='100'><foreignObject x='0' y='0' width='100%' height='100%'><div id="render" style="width: 100px; height: 100px; background: red" xmlns="http://www.w3.org/1999/xhtml"></div></foreignObject></svg>
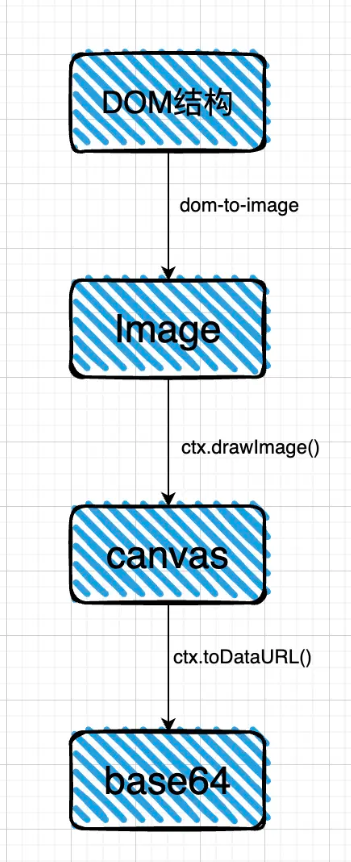
实不相瞒这个就是dom-to-image的核心原理,性能肯定是不错的,因为它是调用浏览器底层的渲染器。
通过这个dom-to-image我们可以很好的解决资源大小和性能这两个瓶颈的点。
三、优化
这个库打包后的产物是umd规范的,并且是统一暴露出来的全局变量,因此不支持treeshaking。

但是很多方法比如toJpeg、toBlob、等方法我们其实都用不到,所以打包了很多我们不需要的产物,于是其实我们可以把核心的实现自己写一遍,使用1-2kb的空间就可以做到这一点。
经过以上的思考我们就可以基本上确定方案了:
基于dom-to-image的原理,实现一个简易的my-dom-to-image,大约只需要100行代码左右就可以做到。
然后将document.body转化为image,再从这个image中截取特定的部分。
好了,以上就是我关于这个需求的一些思考,如果掘友也有一些其他非常有意思的需求,欢迎评论区讨论我们一起头脑风暴啊!!!
利用插件
其实针对截屏,如果只用纯web技术,确实有点麻烦,但是如果说我们利用插件去做就非常简单了,我们只需要借助一个API就可以获取一个tab的截屏数据。
chrome.tabs.captureVisibleTab(
windowId,
{ format: 'png' }
, function(dataUrl) {
const img = new Image();
img.src = dataUrl; // 将图像添加到页面或进行其他操作
document.body.appendChild(img);
});
所以说如果你有精力,可以和你的产品商量一下能不能把这个需求做到一个插件里面,你可以开发一个插件去做这件事情。不必担心不懂插件相关的技术,因为我已经帮你写了一个插件专栏,点击这里查看。里面有插件开发入门的大部分内容,快来看看吧!
四、维护 — 这个内容非重点,可以跳过
9.13日更
文章发布后,针对这个需求有很多掘友提出了新的想法和思路,给思考的掘友们点赞(๑•̀ㅂ•́)و,我大概整理一下评论区的方案:
有一位掘友提到了一个库 rasterizeHTML.js。
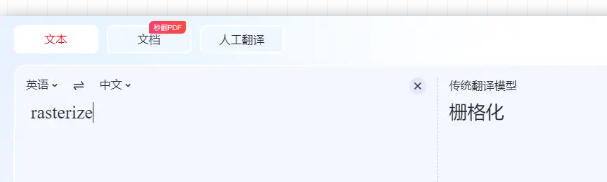
从名字来看是想要栅格化HTML,通俗来讲把HTML画出来的意思,我以前还真不知道还有这个库,学习了,他的核心源码就是下面这一段:

说白了,还是一样,利用svg可以包含html的特点去做的,和dom-to-image的思想差不多。
另外一位掘友提到了一个API:navigator.mediaDevices.getDisplayMedia,我大概试了一下,应该是不满足需求的,因为这个API的调用必须需要用户手动赋予许可才可以,你一调用它,就会弹出赋予权限的提示框,就像下面这样:
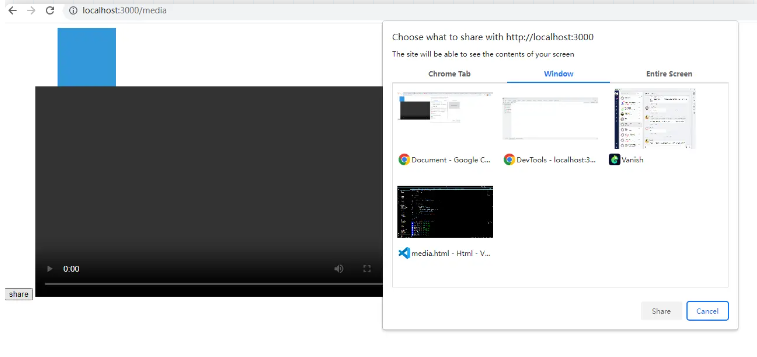
即便用户同意了,可以得到一个MediaStream被称为媒体流的对象,但是这个对象内部肯定封装了屏幕的像素信息,但是压根没把这个东西暴露给用户,反正我找遍了它的几乎所有属性,没看到它把像素信息暴露出来了。它是方便用户直接在video上使用而设计的。可以用它来做类似屏幕共享的功能。
但是既然已经将像素绘制到了video上实际上就可以将其转化为canvas,我们可以像下面这样的方式去做:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>共享屏幕</title>
<style>
.animated-box {
width: 100px;
height: 100px;
background-color: #3498db;
position: relative;
animation-name: slideIn;
animation-duration: 2s; /* 动画持续时间 */
animation-timing-function: ease; /* 动画时间函数 */
animation-fill-mode: forwards; /* 动画结束后保持最终状态 */
animation-iteration-count: infinite;
}
/* 定义动画关键帧 */
@keyframes slideIn {
0% {
left: 100px; /* 起始位置 -100px 左侧 */
}
50% {
left: 0; /* 结束位置 0 左侧 */
}
100% {
left: 100px;
}
}
</style>
</head>
<body>
<div class="animated-box"></div>
<button onclick="share()">share</button>
<video src="" id="video" width="640" height="360" controls></video>
<canvas id="canvasElement" width="640" height="360"></canvas>
<script>
let tracks;
function share() {
try {
navigator.mediaDevices
.getDisplayMedia({ video: true })
.then((mediaStream) => {
const videoElement = document.getElementById("video");
const canvasElement = document.getElementById("canvasElement");
videoElement.srcObject = mediaStream;
const ctx = canvasElement.getContext("2d");
// 在每个AnimationFrame绘制视频帧
function drawFrame() {
ctx.drawImage(
videoElement,
0,
0,
canvasElement.width,
canvasElement.height
);
const imageData = ctx.getImageData(
0,
0,
canvasElement.width,
canvasElement.height
);
// 在 imageData 中获取像素信息
// imageData.data 包含了每个像素的RGBA数据
// 您可以处理这些数据以获取所需的信息
// 例如,获取特定坐标的像素颜色值:imageData.data[(y * imageData.width + x) * 4]
console.log(imageData);
requestAnimationFrame(drawFrame);
}
// 启动绘制循环
requestAnimationFrame(drawFrame);
});
} catch (e) {
console.log("Unable to acquire screen capture: " + e);
}
}
</script>
</body>
</html>
演示效果:

本文转载于:
https://juejin.cn/post/7276694924137463842
如果对您有所帮助,欢迎您点个关注,我会定时更新技术文档,大家一起讨论学习,一起进步。

1.本站内容仅供参考,不作为任何法律依据。用户在使用本站内容时,应自行判断其真实性、准确性和完整性,并承担相应风险。
2.本站部分内容来源于互联网,仅用于交流学习研究知识,若侵犯了您的合法权益,请及时邮件或站内私信与本站联系,我们将尽快予以处理。
3.本文采用知识共享 署名4.0国际许可协议 [BY-NC-SA] 进行授权
4.根据《计算机软件保护条例》第十七条规定“为了学习和研究软件内含的设计思想和原理,通过安装、显示、传输或者存储软件等方式使用软件的,可以不经软件著作权人许可,不向其支付报酬。”您需知晓本站所有内容资源均来源于网络,仅供用户交流学习与研究使用,版权归属原版权方所有,版权争议与本站无关,用户本人下载后不能用作商业或非法用途,需在24个小时之内从您的电脑中彻底删除上述内容,否则后果均由用户承担责任;如果您访问和下载此文件,表示您同意只将此文件用于参考、学习而非其他用途,否则一切后果请您自行承担,如果您喜欢该程序,请支持正版软件,购买注册,得到更好的正版服务。
5.本站是非经营性个人站点,所有软件信息均来自网络,所有资源仅供学习参考研究目的,并不贩卖软件,不存在任何商业目的及用途










暂无评论内容