
引言
嘿,大家好!今天我想聊聊我最近在前端开发中遇到的一个头疼的问题,以及我是如何一步步解决它的。如果你也在使用Websocket实现AI会话,或许你会遇到类似的问题。
项目背景
我最近在捣鼓一个开源项目,项目地址:GitHub – chatpire/chatgpt-web-share: ChatGPT Plus 共享方案。ChatGPT Plus / OpenAI API sharing solution. 感谢大佬的开源。原本它支持多种AI聊天接口,但我把它简化了,只保留了OpenAI API,专注于特定功能的开发。
遇到的挑战
在开发过程中,我发现随着聊天轮次的增加,应用的响应速度越来越慢,内存占用也异常高。这让我有点头疼,毕竟用户体验是最重要的。
初次尝试:内存分析
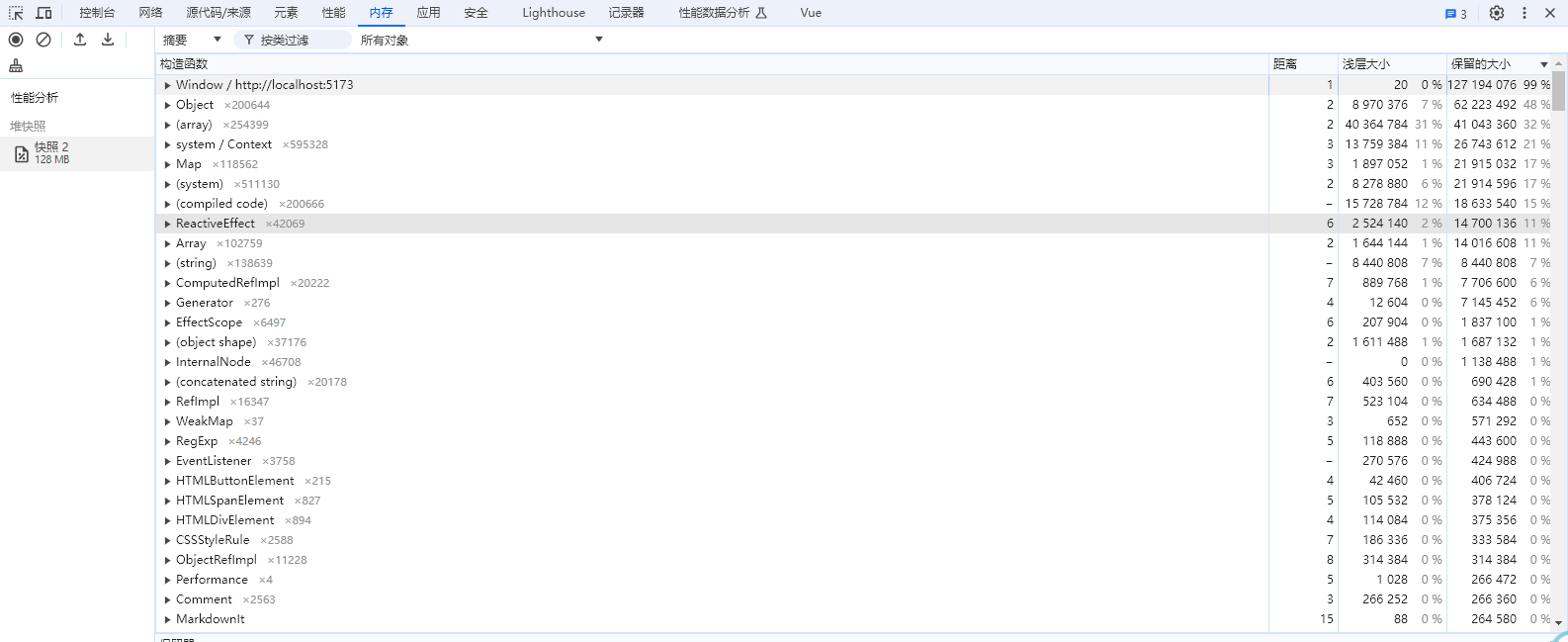
我尝试用开发者工具去分析内存,但说实话,我那半吊子的前端水平让我有点摸不着头脑。我在网上搜罗了各种教程,但似乎都不太对症。
思路转变:性能优化
我意识到问题可能出在渲染大量echarts图表上,于是尝试引入了虚拟列表技术。想法是好的,但实际操作起来却问题多多,比如消息丢失、滚动条乱跳等等。
再次调整:简化数据处理
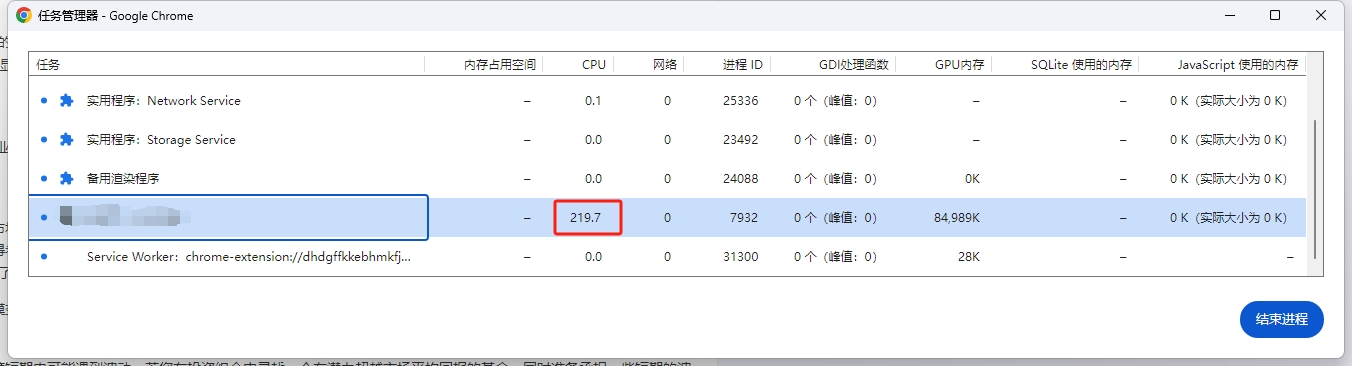
在放弃了虚拟列表后,我决定换个角度思考。我发现在AI回复时,CPU占用率特别高。这让我意识到,可能需要重新设计后端和前端的数据交互方式。
技术实现
我调整了后端逻辑,让它只发送最新的消息增量,而不是每次都发送全量消息。这样不仅减少了网络传输的负担,也减轻了前端的内存压力。前端代码也做了相应的优化,避免了重复的消息处理。
const index = currentRecvMessages.value.findIndex((msg) => msg.id === message.id); if (index === -1) { currentRecvMessages.value.push(message); } else {
// 原来的 // currentRecvMessages.value[index] = message;
// 新的 currentRecvMessages.value[index].content!.text += message.content!.text; }
效果
经过这些调整,应用的响应速度和内存占用都有了显著的改善,用户体验也大幅提升。现在,CPU占用通常在10-35%之间,但接收echarts图表时,会飙升至150-300%。这显然是下一步需要优化的点。
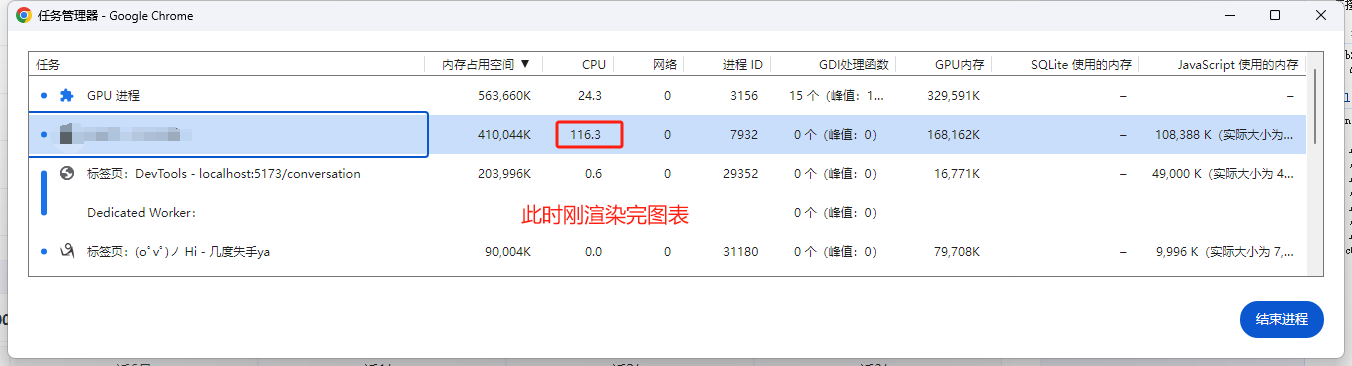
未来计划
我猜测,CPU占用率飙升的原因可能是需要同时渲染30张图表。我计划进一步优化图表的渲染方式,比如分批渲染或使用更高效的图表库。如果你有任何建议或想法,欢迎在评论区告诉我!
结语
这次的经历让我深刻认识到,优化是一个不断试错和调整的过程。我相信,通过持续学习和实践,我能成为一名更出色的全栈工程师。如果你有任何建议或想法,欢迎在评论区告诉我!
1.本站内容仅供参考,不作为任何法律依据。用户在使用本站内容时,应自行判断其真实性、准确性和完整性,并承担相应风险。
2.本站部分内容来源于互联网,仅用于交流学习研究知识,若侵犯了您的合法权益,请及时邮件或站内私信与本站联系,我们将尽快予以处理。
3.本文采用知识共享 署名4.0国际许可协议 [BY-NC-SA] 进行授权
4.根据《计算机软件保护条例》第十七条规定“为了学习和研究软件内含的设计思想和原理,通过安装、显示、传输或者存储软件等方式使用软件的,可以不经软件著作权人许可,不向其支付报酬。”您需知晓本站所有内容资源均来源于网络,仅供用户交流学习与研究使用,版权归属原版权方所有,版权争议与本站无关,用户本人下载后不能用作商业或非法用途,需在24个小时之内从您的电脑中彻底删除上述内容,否则后果均由用户承担责任;如果您访问和下载此文件,表示您同意只将此文件用于参考、学习而非其他用途,否则一切后果请您自行承担,如果您喜欢该程序,请支持正版软件,购买注册,得到更好的正版服务。
5.本站是非经营性个人站点,所有软件信息均来自网络,所有资源仅供学习参考研究目的,并不贩卖软件,不存在任何商业目的及用途








暂无评论内容