
RAG的部分我们之前讨论过信息召回的多样性,信息密度和质量,主要集中在召回,融合,粗排的部分。这一章我们集中看下精排的部分。粗排和精排的主要差异其实在于效率和效果的balance。粗排模型复杂度更低,需要承上启下,用较低复杂度的模型,在大幅度缩小召回候选量级的基础上,和精排的排序一致性做尽可能的对齐,保证精排高质量内容不被过滤。而精排模型复杂度更高,可以使用更复杂的模型来尽可能地拟合最终的目标排序。在RAG任务中,最终目标就是候选内容可以回答问题,客观评估就是推理引用率。
精排模型的训练目标常用的有几种,有全局优化的ListWise,有每个item独立拟合ctr等直接目标的pointwise,还有对比优化的pairwise。在RAG的排序模块,也有多篇论文针对排序目标和样本的标注方式使用以上的不同方案进行了尝试,以下方案均可以直接使用大模型做精排,也可以使用大模型来构建微调样本训练小模型~
PointWise
- HELM:Holistic Evaluation of Language Models
- UPR:Improving Passage Retrieval with Zero-Shot Question Generation
先说pointwise也就是每条召回内容,都独立判断该内容能多大程度上回答query的问题,既query和content的相关性。
那最直观的方案就是把query和content一起输入大模型让模型判断是否相关,也就是HELM中使用的few-shot指令判别方案。使用以下指令大模型推理的YES,NO的token概率来对内容进行排序。
Given a passage and a query, predict whether the passage includes an answer to the query by producing either ‘Yes‘ or ‘No‘.
{{few_shot}}
Passage: {{passage}}
Query: {{query}}
Does the passage answer the query?
Answer:
如果说上面的方案是针对每条内容候选计算P(query,content)的联合概率,那考虑query对于所有content是固定的,那我们也可以选择计算P(content|query)的条件概率。
但考虑内容中的噪声会比较大,既有相关也有无关信息,所以我们放松bayesian的假设,通过计算P(query|content)来近似P(content|query),也就是用给定content下query的概率来衡量query和content的相似度。
UPR论文直接使用大模型,基于以下的prompt模版,计算query每个字的解码概率取平均作为P(query|content)的近似,因为可以并行解码,所以这个方案虽然用大模型但是也不算慢。
Passage: {{passage}}. Please write a question based on this passage.
以及是不是看着很眼熟,和之前在LLM Agent之再谈RAG的召回信息密度和质量中提到的长文本压缩方案的LongLLMLingua是一个思路。只不过LongLLMLingua使用的指令是”we can get the answer to this question in the given documents”
Listwise
- RankVicuna: Zero-Shot Listwise Document Reranking with Open-Source Large Language Models
- RankGPT:Is ChatGPT good at search? Investigating large language models as re-ranking agent
- https://github.com/sunnweiwei/RankGPT
RankGPT提出了基于permutation的大模型排序方案,模型会输入多个content上文,并使用指令要求LLM根据内容的关联性按顺序输出内容序号, prompt模版如下
This is RankGPT, an intelligent assistant that can rank passages based on their relevancy to the
query.
The following are {{num}} passages, each indicated by number identifier []. I can rank them based
on their relevance to query: {{query}}
[1] {{passage_1}}
[2] {{passage_2}}
(more passages) ...
The search query is: {{query}}
I will rank the {{num}} passages above based on their relevance to the search query. The passages
will be listed in descending order using identifiers, and the most relevant passages should be listed
first, and the output format should be [] > [] > etc, e.g., [1] > [2] > etc.
The ranking results of the {{num}} passages (only identifiers) is:
而所谓Permutation是考虑到LLM的上文长度有限,因此对N条上文内容进行了分组,组和组之间是有重叠的划分,每次只让模型对一组数据进行排序。listwise效果虽好,但是也有不少缺点
- 推理上文长度的限制
- 输入内容顺序会影响推理结果
- 输出推理耗时较高
- 多次预测的稳健性不高会出现排序冲突
- 对模型能力的要求较高
Pairwise
- Large Language Models are Effective Text Rankers with Pairwise Ranking Prompting
相比前面的pointwise依赖模型输出概率是well-calibrated,listwise依赖模型有较好的排序能力,pairwise对模型的要求会放松不少。
论文使用以下prompt让模型对两个内容进行对比,输出A/B的结果,这里论文也是使用了prob 概率,不过相对于pointwise使用所有内容的prob概率直接进行排序,pairwise会两两进行对比,同时每次都会swap内容的顺序,得到AB,BA的两次对比的token推理概率。
Given a query {query}, which of the following two passages is more relevant to the query?
Passage A: {document1}
Passage B: {document2}
Output Passage A or Passage B:
那如何使用以上两两对比的结果,论文给出了三种排序方案: all pairs,heap sort和bubble sort
All pairs使用内容间两两对比的结果对所有内容进行打分,两两对比时,如果(AB),(BA)模型均给出了A>B的一致判断则A得一分,如果两次结果矛盾则A,B各得0.5分。所以其实论文把prob概率打分进行了局部的ranking处理,降低了因为模型预测概率不是well-calibrated带来的结果偏差。当然All Pairs的缺点很明显,做一次整体排序,是(N^2)的请求复杂度。
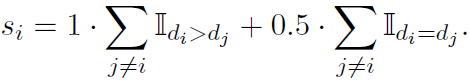
Heap sort就是使用排序算法,把复杂度缩减到了O(NlogN),而bubble sort就是冒泡排序的实现逻辑,同时考虑到精排往往只保留Top-k排名最高的item即可,因此只需要两两对比交换顺序K次,所以复杂度是O(NK)。
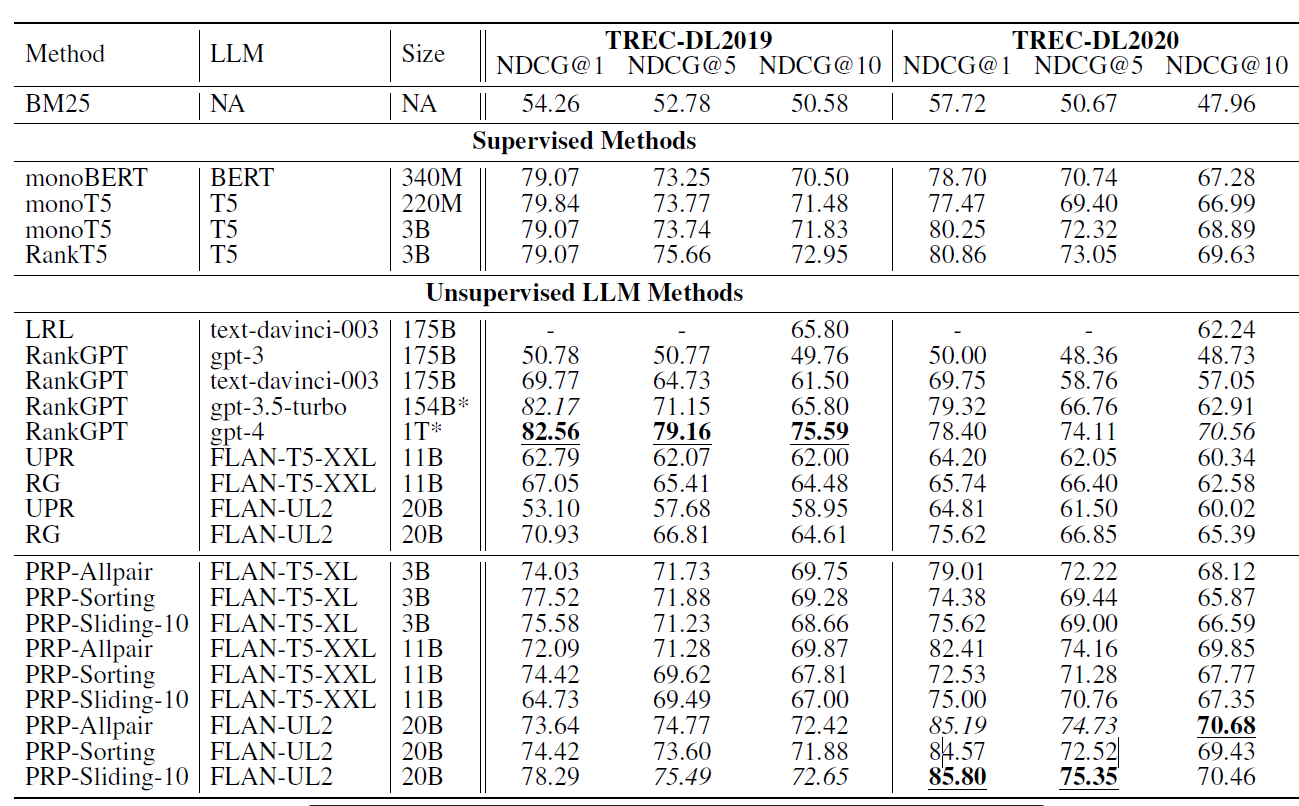
效果上论文和前面的point-wise的UPR,list-wise的RankGPT都做了对比,除了打不过gpt4吧,使用20B的FlAN-UL2基本能和gpt3.5效果差不多。并且对比listwise,pair-wise的对比方案,对输入内容顺序的敏感度很低,同时对模型能力的要求也比较低,小模型也能有和大模型相当的表现。
SetWise
- A Setwise Approach for Effective and Highly Efficient Zero-shot Ranking with Large Language Models
- https://github.com/ielab/llm-rankers
最后一篇介绍setwise,其实是上面listwise和pairwise的结合体,它使用了listwise的打分方式,也借鉴了pairwise使用heap sort和bubble sort筛选topK文档的思路,其实还用了pointwise使用大模型输出概率分布的思路。哈哈感觉其实算是个工程化实现的改进,简单说一下
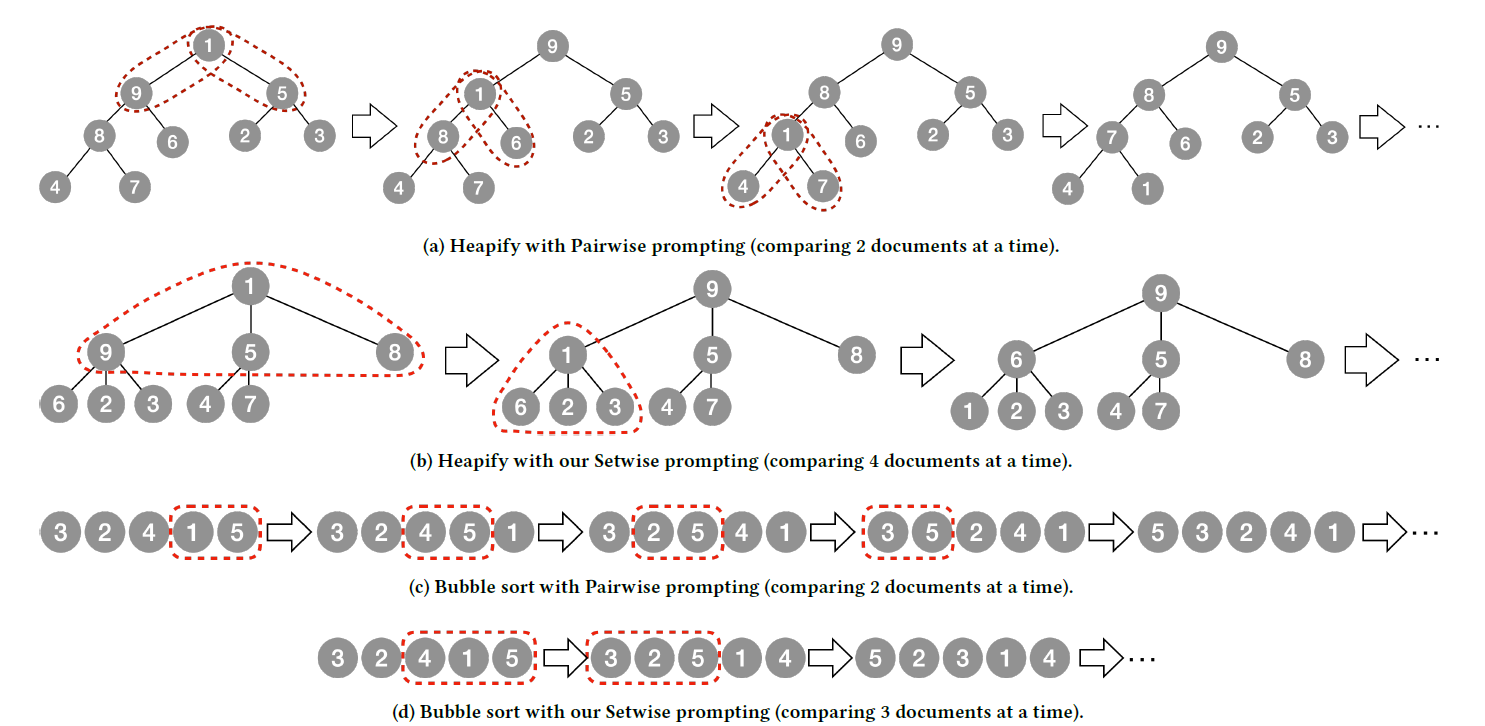
前面的listwise打分,需要大模型对所有内容进行一次性的排序,不仅有上文长度的限制,输入内容顺序对结果的影响,推理比较慢的问题,同时对模型来说本身难度也较高,会出现多次推理顺序矛盾的情况。因此不妨把内容分成很多个小组,降低输入长度,同时把输出排序改为输出小组内最相关的文档序号,这样既降低推理延时,也同时可以使用输出token的logits分布来对组内的多个文档进行打分。
然后基于小组内的打分,同样是使用bubble sort,对比pairwise的实现逻辑每次对比交换都需要计算大模型对比两个文档的相关性,setwise可以一次对比组内的3-4篇文档,在效率上会有进一步提升,对比如下图
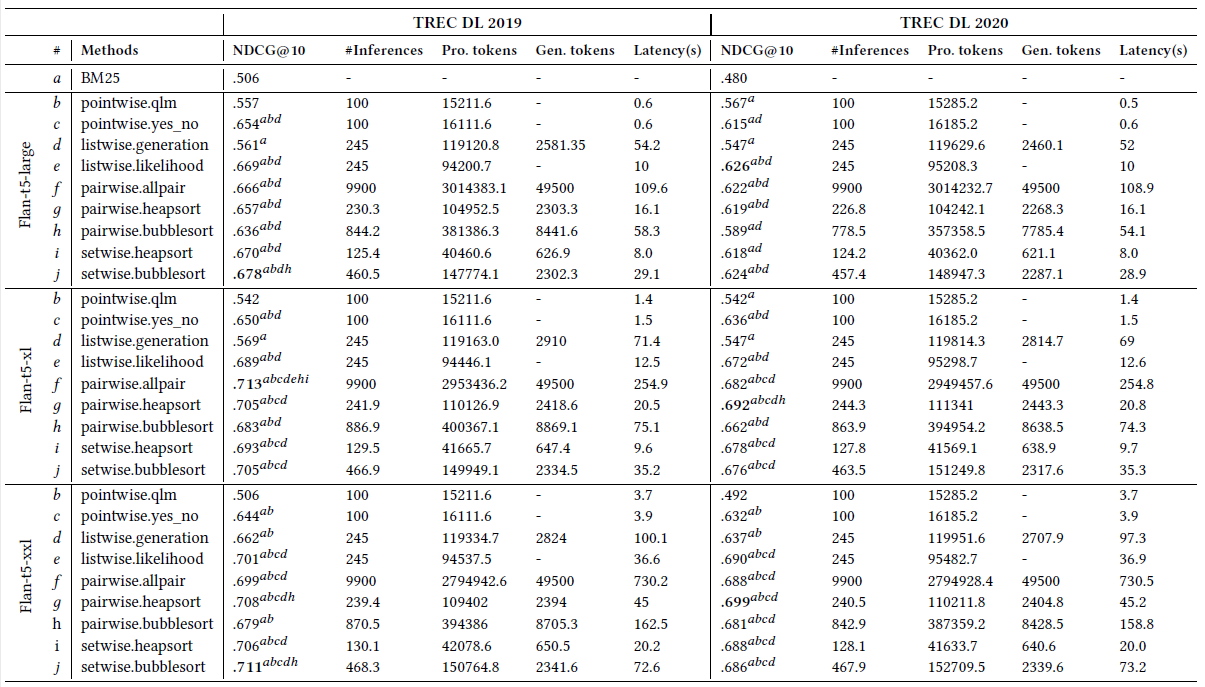
效果上论文使用NDCG@10作为评估指标(上角标是setwise相对前面哪些方法有显著的指标提升),下图一是不同模型大小的Flan-t5使用不同排序方案的效果&效率对比,虽然pointwise的latency是最低的,但是效果也是最差的,而pairwise效果是最好的,但latency也是最高的。在兼顾排序效果和latency的方案中listwise-likelihood和setwise heapsort看起来是更合适的方案。
想看更全的大模型相关论文梳理·微调及预训练数据和框架·AIGC应用,移步Github >> DecryPrompt
彩蛋
最近想做个自己的博客网站,于是用传说中一句话就能构建功能完备的web页面的,网页模拟生成器websim.ai试了下,下面是效果图,感觉效果还不戳哦,大家觉得嘞~

1.本站内容仅供参考,不作为任何法律依据。用户在使用本站内容时,应自行判断其真实性、准确性和完整性,并承担相应风险。
2.本站部分内容来源于互联网,仅用于交流学习研究知识,若侵犯了您的合法权益,请及时邮件或站内私信与本站联系,我们将尽快予以处理。
3.本文采用知识共享 署名4.0国际许可协议 [BY-NC-SA] 进行授权
4.根据《计算机软件保护条例》第十七条规定“为了学习和研究软件内含的设计思想和原理,通过安装、显示、传输或者存储软件等方式使用软件的,可以不经软件著作权人许可,不向其支付报酬。”您需知晓本站所有内容资源均来源于网络,仅供用户交流学习与研究使用,版权归属原版权方所有,版权争议与本站无关,用户本人下载后不能用作商业或非法用途,需在24个小时之内从您的电脑中彻底删除上述内容,否则后果均由用户承担责任;如果您访问和下载此文件,表示您同意只将此文件用于参考、学习而非其他用途,否则一切后果请您自行承担,如果您喜欢该程序,请支持正版软件,购买注册,得到更好的正版服务。
5.本站是非经营性个人站点,所有软件信息均来自网络,所有资源仅供学习参考研究目的,并不贩卖软件,不存在任何商业目的及用途







暂无评论内容