
位运算
位运算和逻辑运算区别
位运算是一位对应一位的对所有位逐一进行运算(逐比特位进行运算).逻辑运算是以计算表达式的真假为主进行运算.
位运算的几点注意
-
机器都是使用补码进行运算,遇到负数时不要混淆
-
~(-1)的结果是0,~(0)的结果是-1,按位取反所有位都要取反,不论是否有符号.
异或的运算规则
-
运算规则: 相同为假, 相异为真
0000 0000 ... 0100 0000 0000 ... 0011
0000 0000 … 0111
printf(“%dn”,4^3); //结果:7
2. 任何数据和0异或,结果都是它本身
```C
printf("%dn",1 ^ 0); //结果:1
printf("%dn",6 ^ 0); //结果:6
printf("%dn",7 ^ 0); //结果:7
printf("%dn",-1 ^ 0); //结果:-1
-
异或运算支持交换律和结合律
printf("%dn",5 ^ 5 ^ 4); //结果:4 printf("%dn",5 ^ 4 ^ 5); //结果:4 => 交换律 printf("%dn",5 ^ (5 ^ 4)); //结果:4 => 结合律 -
异或自己的结果是0 (消消乐)
异或的经典问题:两数交换
问题:两个变量int a = 10; int b = 20;再不使用第三个变量的前提下,怎么讲两个数进行交换?
方法一:加减法
a = a + b; // ①
b = a - b; // ②
a = a - b; // ③
解析:
(在计算机运算中,运算过程可以当作第三个变量,只是这个过程必须赋值才有意义,我们可以计算出各种组合的值用来匹配和验证)
- ①是将a和b的值保存到a中.原理:a+b-b = a,只要b还在,a就不会丢失.(借助a当作第三个容器)
- ②:验证发现新a-b = 旧a,赋值给b后就能实现b变成了旧a.
- ③:a变量保存着旧a和旧b,新b保存旧a,于是新a-新b就等于旧b.
缺点: 加法可能会有比特位递增,如果发生溢出,则会发生截断,导致数据丢失.所以这种方法仅适用于一定范围的数据
方法二:异或法
a = a ^ b; //①
b = a ^ b; //②
a = a ^ b; //③
一次记住它: 等号左边是aba,右边全是a^b
解析:(消消乐)
- ①是a和b的值保存在a中.原理:
a^b^b=a,只要b还在a就不会丢失. - ②: 新a=
10^20,对b=a^b=10^20^20,利用结合律,先计算20^20,就可以得到a,然后再赋值给b,b变量就得到了旧a的值. - ③:有了旧a的值,交换律+消消乐把新a中旧a的值消掉,新a就可以得到旧b的值,完成交换.
相对于加减法的优点: 异或不会进位,不会出现比特位递增、溢出的问题
位操作建议使用宏定义好后使用
// 0|0 = 0 ; 0|1 = 1 // 规律:任何数或0结果都是它本身 //用途:
// 1|0 = 1 ; 1|1 = 1 // 规律:任何数或1,结果都是被设置为1 //用途:特定 比特位 置1
// 组合用途:让特定比特位置1,其他位不变
// 0&0 = 0 ; 0&1 = 0; // 规律:任何书与0,结果都是被设置成0 //用途:特定比特位置0
// 1&0 = 0 ; 1&1 = 1; // 规律:任何书与1,结果都是它本身 //用途:获取特定比特位的值
// 组合用途:没有干扰地获取特定比特位的值
//一般都是用1(000...1)比较方便,通过移动1的位置,加上不同的位运算符,能够实现不同的功能.
#define SETBIT(x,n) (x |= (1打印结果:
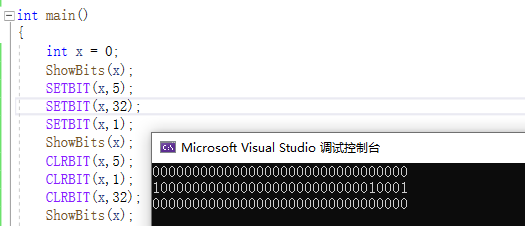
位运算整型提升问题
如图

为什么对char类型位操作后进行sizeof,计算出来的大小会改变? 难道位操作后就不是char类型吗? 并不是
解析:
首先,C语言关键字的作用是在编译期间就确定好了.sizeof是C语言关键字,他在编译期间就确定好了大小.换言之,sizeof这个计算过程是在编译期间做的,通过反汇编,我们能看到汇编代码中sizeof不存在,只显示了一个常数,这也说明sizeof不是一个函数,它在编译期间就已经计算好了.
其次,不论任何位运算符,目标都是要计算机进行计算的,需要加载到CPU中进行计算. 但是计算的数据都是存放在内存中,要计算都必须从内存加载到cpu中.拿到CPU那里? 答案是cpu的寄存器中.而寄存器本身,随着计算机位数的不同,寄存器的位数也不同.一般在32位下.寄存器的位数是32位.因为char是8位,读到寄存器中,只能填补低8位,还有高24位没有数据,因此就会触发整型提升,然后计算,这也是说明数据在计算机中并非以char类型运行,都是以整型方式运行的.综上这一些系列步骤,编译成的汇编代码就是整型提升后的大小了
汇编部分截图:
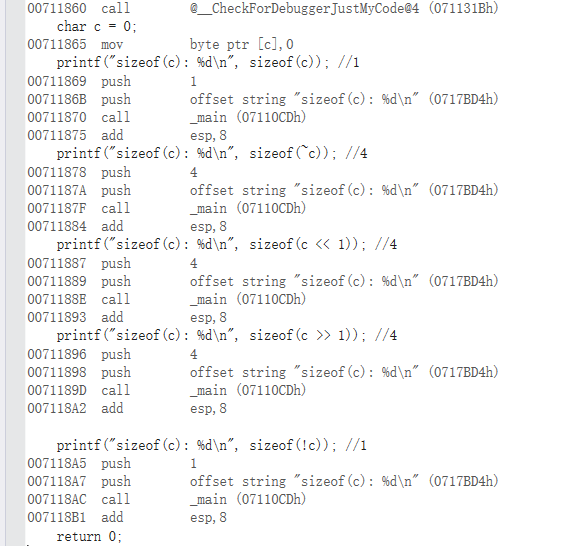
在vs中还有一种现象:sizeof(!c)大小不同编译器大小不一样
如图:
 按照前面四种类型的分析,理论上也应该是4,而vs是1,gcc是4,这也是说明了具体的整型提升方式也是由编译器决定的,原理大致就是这样.
按照前面四种类型的分析,理论上也应该是4,而vs是1,gcc是4,这也是说明了具体的整型提升方式也是由编译器决定的,原理大致就是这样.
左移和右移
概念
(左移): 最高位丢弃,最低位补零
>>(右移):
- 无符号数:最低位丢弃,最高位补零[逻辑右移]
- 有符号数:最低位丢弃,最高位补符号位[算术右移]
(无符号数,要保证它始终无符号,所以逻辑右移高位补零)
右移相当于除以2,但有特殊情况,有符号数且为-1时,右移数值不会改变
左移始终补零,所以都是乘以2
实际上,浮点数的左移右移坑还是很多,尽量不使用浮点数.非要使用,先在编译器下提前验证好再使用
移位运算容易误解成移位赋值
移位运算也和其他运算一样,加载到cpu中计算,并不会写回到内存中,只有赋值才能将数据写回内存
int a = 10;
a 数据在做计算时,要将数据内存加载到CPU寄存器中,在CPU内的数据改变,是不会影响到内存中的数据,这里会有短暂的时间CPU与内存的值是不一样的,直到我们把结果写回到内存中.在加载到CPU直到写回内存这段过程的每一段都有可能体现在代码中,具体取决于编译器怎么处理(不同编译器计算路径不唯一).
1.本站内容仅供参考,不作为任何法律依据。用户在使用本站内容时,应自行判断其真实性、准确性和完整性,并承担相应风险。
2.本站部分内容来源于互联网,仅用于交流学习研究知识,若侵犯了您的合法权益,请及时邮件或站内私信与本站联系,我们将尽快予以处理。
3.本文采用知识共享 署名4.0国际许可协议 [BY-NC-SA] 进行授权
4.根据《计算机软件保护条例》第十七条规定“为了学习和研究软件内含的设计思想和原理,通过安装、显示、传输或者存储软件等方式使用软件的,可以不经软件著作权人许可,不向其支付报酬。”您需知晓本站所有内容资源均来源于网络,仅供用户交流学习与研究使用,版权归属原版权方所有,版权争议与本站无关,用户本人下载后不能用作商业或非法用途,需在24个小时之内从您的电脑中彻底删除上述内容,否则后果均由用户承担责任;如果您访问和下载此文件,表示您同意只将此文件用于参考、学习而非其他用途,否则一切后果请您自行承担,如果您喜欢该程序,请支持正版软件,购买注册,得到更好的正版服务。
5.本站是非经营性个人站点,所有软件信息均来自网络,所有资源仅供学习参考研究目的,并不贩卖软件,不存在任何商业目的及用途







暂无评论内容